Hessian 协议解释与实战(三):字符串

前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和
null等三种类型的数据的处理。Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
在上一篇文章 Hessian 协议解释与实战(二):长整型、二进制数据与 Null 中研究了长整型、二进制数据与 null 等三种数据类型的处理方式。接下来,我们再来介绍字符串的处理情况。
基础工具方法
基础工具方法就不再赘述,请直接参考 Hessian 协议解释与实战(一):布尔、日期、浮点数与整数:基础工具方法 中提到的几个方法。
字符串
在 Hessian 2.0 序列化协议(中文版):字符串类型数据 中对字符串类型的数据做了描述。总得来说,还算比较清楚。但是一些细节不是特别清楚,比如“以 UTF-8 编码的 16 位 Unicode 字符串”,再比如,四个字节的 UTF-8 怎么被 16 位 Unicode 字符串表示等。这里深究一下。
在讲述 Hessian 如果处理字符串之前,我们先简要介绍一些编码与字符串的基础知识,方便后续内容展开。
编码与字符集概述
关于字符串编码有非常非常多的计算机底层知识。在探究的过程中,还是费了不少力气。关于 Unicode、UTF-8、UTF-16(以及相关变种 UTF-16BE 和 UTF-166LE)等相关知识有非常非常多,这里不展开讲解。那里提到了相关知识,会简单诉说一下,只是做些铺垫工作。后续有机会,再发文细讲。
ASCII 码
ASCII 是 American Standard Code for Information Interchange 的简称,定义了128个字符的编码规则,其字符集合叫 ASCII 字符集。完整列表如下:

Unicode
ASCII 码是美国制定出来针对英语的编码标准;后来,中国发展出来自己的 GB2312,后来为了增加对繁体字的支持,又扩展出来了 GB18030。其他国家也发展出来自己的编码标准。为了解决不同国家间却经常出现编码不相容的情况,发展出了 Unicode 编码。
在文字处理方面,Unicode 为每一个字符而非字形定义唯一的代码(即一个整数)。换句话说,统一码以一种抽象的方式(即数字)来处理字符,并将视觉上的演绎工作(例如字体大小、外观形状、字体形态、文体等)留给其他软件来处理。D瓜哥的理解就是给每个字符分配了一个身份证号。
在表示一个 Unicode 的字元时,通常会用 “U+” 然后紧接着一组十六进位的数字来表示这一个字元。
Unicode 的实现方式称为 Unicode转换格式(Unicode Transformation Format,简称为UTF)。目前,常用的为 UTF-8 和 UTF-16。
UTF-8 编码
Unicode 和 UTF-8 的转换关系比较统一。用表格展示:

UTF-16 编码
UTF-16 目前可以分为两种转化格式:
如
U ∈ [U+0000, U+D7FF]orU ∈ [U+E000, U+FFFF],则 UTF-16 和 Unicode 相同如果
U ∈ [U+010000, U+10FFFF],则转化关系略复杂,具体如下:// Basic Multilingual Plane (BMP) U ∈ [U+0000, U+D7FF] or U ∈ [U+E000, U+FFFF] U+ⒶⒷⒸⒹ → 0xⒶⒷⒸⒹ // Supplementary Planes U ∈ [U+010000, U+10FFFF] // U - 0x10000 之后,只有 20 位 U' = ⑲⑱⑰⑯⑮⑭⑬⑫⑪⑩ ⑨⑧⑦⑥⑤④③②①⓪ // U - 0x10000 W₁ = 110110⑲⑱ ⑰⑯⑮⑭⑬⑫⑪⑩ // 0xD800 + ⑲⑱⑰⑯⑮⑭⑬⑫⑪⑩ W₂ = 110111⑨⑧ ⑦⑥⑤④③②①⓪ // 0xDC00 + ⑨⑧⑦⑥⑤④③②①⓪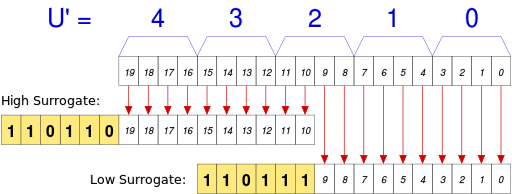
编码之后,每个字符的编码范围是
W ∈ [0xD800, 0xDFFF],其中,high surrogateW₁ ∈ [0xD800, 0xDBFF], low surrogateW₂ ∈ [0xDC00, 0xDFFF],正好可以 BMP 的字区分开。
铺垫工作基本够用了,下面开始介绍 Hessian 对字符串的处理。
Hessian 对字符串的基本处理
坦白讲,Hessian 对字符串处理的描述一脸懵逼。所以,还是直接结合 Hessian 的代码,来说明一下 Hessian 中对单个字符怎么处理的。直接上代码:
public void printString(String v, int strOffset, int length)
throws IOException
{
int offset = _offset;
byte []buffer = _buffer;
for (int i = 0; i < length; i++) {
if (SIZE <= offset + 16) {
_offset = offset;
flushBuffer();
offset = _offset;
}
char ch = v.charAt(i + strOffset);
if (ch < 0x80)
buffer[offset++] = (byte) (ch);
else if (ch < 0x800) {
buffer[offset++] = (byte) (0xc0 + ((ch >> 6) & 0x1f));
buffer[offset++] = (byte) (0x80 + (ch & 0x3f));
}
else {
buffer[offset++] = (byte) (0xe0 + ((ch >> 12) & 0xf));
buffer[offset++] = (byte) (0x80 + ((ch >> 6) & 0x3f));
buffer[offset++] = (byte) (0x80 + (ch & 0x3f));
}
}
_offset = offset;
}这段代码中,关于字符(char)的处理有三个分支,分开来说明一下:
第一个分支条件
ch < 0x80,这里的0x80等价于8*16 + 0 = 128,正好是 ASCII 编码范围内的字符。所以,这个分支的意思就很明确了: ASCII 编码范围内的字符直接使用其编码来作为序列化的结果。另外,UTF-8 在 ASCII 编码范围内,与之相同。所以,这和标准中提到的使用 UTF-8 编码是没有冲突的。第二个分支
ch < 0x800,坦白讲,最初看到这个数字是懵逼的。不知道这个0x800。在查相关资料时,看到了 UTF-8 编码的氛围划分,在 UTF-8 - Wikipedia 中看到有U+0800。在其上的一行内容显示为两个字节的 UTF-8 编码范围是U+0080~U+07FF,其二进制表示是110xxxxx+10xxxxxx。这里的U+07FF和0x800正好相邻,结合序列化的结果来看,两个字节表示的 UTF-8 的字符直接是使用 UTF-8 编码来作为其序列化结果。所以,从这点可以看出,这里的0x800就是两个字节表示的 UTF-8 的字符的上限。另外, UTF-8 编码范围的U+0080和上面的0x80也是相吻合的。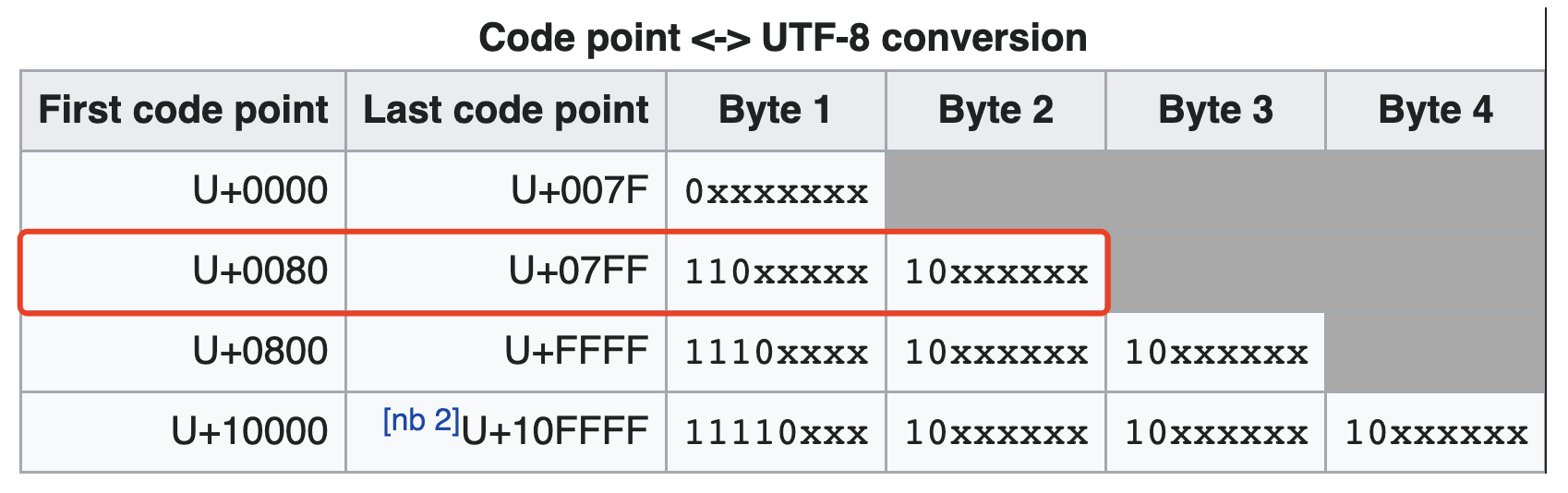
第三个情况就比较复杂了。我们先来看看 《The Java® Language Specification》 中怎么来定义字符的。这里直接摘录规范原文:
The Unicode standard was originally designed as a fixed-width 16-bit character encoding. It has since been changed to allow for characters whose representation requires more than 16 bits. The range of legal code points is now U+0000 to U+10FFFF, using the hexadecimal U+n notation. Characters whose code points are greater than U+FFFF are called supplementary characters. To represent the complete range of characters using only 16-bit units, the Unicode standard defines an encoding called UTF-16. In this encoding, supplementary characters are represented as pairs of 16-bit code units, the first from the high-surrogates range (U+D800 to U+DBFF), and the second from the low-surrogates range (U+DC00 to U+DFFF).
The Java programming language represents text in sequences of 16-bit code units, using the UTF-16 encoding.
— The Java® Language Specification
Java SE 17 Edition从这个规范中可以看出,Java 使用 UTF-16 编码来表示文本。
另外,在 UTF-16 - Wikipedia 中有如下描述:
Code points from the other planes (called Supplementary Planes) are encoded as two 16-bit code units called a surrogate pair。
……
Java originally used UCS-2, and added UTF-16 supplementary character support in J2SE 5.0.
— UTF-16
Wikipedia从这些描述中,可以看出,在 Java 中,在表示 BMP (Basic Multilingual Plane) 的字符时,使用一个
char字符来表示,而且char值等于字符的 UTF-16 编码;在表示除 BMP 之外的 supplementary 字符时,使用两个char表示,两个char的值是 UTF-16 编码。基本的铺垫工作已经够了,我们来结合示例看一下 Hessian 对字符串的处理过程。
/**
* @author D瓜哥 · https://www.diguage.com/
*/
@Test
public void testString() throws Throwable {
// 单字节字符串
stringTo("D");
// 双字节字符串
stringTo("Å");
// 三字节字符串
stringTo("瓜");
// 四字节字符串
stringTo("😂");
// 😂 = U+1f602
// 第一步,先将 Unicode 转换成 UTF-16 编码;
// 对于超过 BMP 的字符,UTF-16 会将其拆
// 分成两个字符来处理。由于 Java 内部,char
// 类型的数据就是使用 UTF-16 编码的,所以,
// 这一步已经提前完成,无需再做处理。
// (打开调试,查看 char 的内容即可确认)
// 这里演示一下从 Unicode 转 UTF-16 的过程:
// U+1f602 - 0x10000 = 0x0f602
// 0x0f602 = 00 0011 1101, 10 0000 0010
// 00 0011 1101 + 0XD800
// = 00 0011 1101
// + 11011000 0000 0000
// ----------------------
// = 11011000 0011 1101
// = d83d
//
// 10 0000 0010 + 0xDC00
// = 10 0000 0010
// + 11011100 0000 0000
// ----------------------
// = 11011110 0000 0010
// = de02
//
// 第二步,`char` 值大于等于 `0x800` 的 `char`,会将其
// “值”当做 Unicode 然后转换成“3个字节的UTF-8”。
// 如果是需要两个 `char` 表示的字符,则当做两个 “Unicode 值”
// 处理,则 会转成两个“3 个字节的 UTF-8”,就是六个字节。
// 注:这里的“3个字节的UTF-8”,并不是通常说的 UTF-8 编码,
// 只是借用了“3个字节的UTF-8”的编码格式,徒有其表而已。
// 11011000 0011 1101 → 11101101 10100000 10111101
// 11011110 0000 0010 → 11101101 10111000 10000010
// 转换算法见上面的“Unicode 与 UTF-8 的转换”图表。
// 大家可以试试 👍 的转换: 👍 = U+1F44D
stringTo("👍");
// 更长久的长字符串处理示例
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Hessian2Output out = getHessian2Output(bos);
out.writeString("D瓜哥");
out.writeString("https://www.diguage.com");
out.writeString("👍👍👍,老李卖瓜,自卖自夸,😂😂😂");
out.close();
byte[] hessianBytes = bos.toByteArray();
ByteArrayInputStream bais = new ByteArrayInputStream(hessianBytes);
Hessian2Input hessian2Input = getHessian2Input(bais);
String s1 = hessian2Input.readString();
System.out.println(s1);
String s2 = hessian2Input.readString();
System.out.println(s2);
String s3 = hessian2Input.readString();
System.out.println(s3);
hessian2Input.close();
bais.close();
}
/**
* @author D瓜哥 · https://www.diguage.com/
*/
public void stringTo(String value) throws Throwable {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Hessian2Output out = getHessian2Output(bos);
out.writeString(value);
out.close();
byte[] result = bos.toByteArray();
System.out.println("\n== string: " + value + " ==");
byte[] utf8Bytes = value.getBytes(StandardCharsets.UTF_8);
System.out.println("== string: value UTF-8 bytes ==");
printBytes(utf8Bytes);
byte[] utf16Bytes = value.getBytes(StandardCharsets.UTF_16);
System.out.println("== string: value UTF-16 bytes ==");
printBytes(utf16Bytes);
byte[] utf16beBytes = value.getBytes(StandardCharsets.UTF_16BE);
System.out.println("== string: value UTF-16BE bytes ==");
printBytes(utf16beBytes);
byte[] utf16leBytes = value.getBytes(StandardCharsets.UTF_16LE);
System.out.println("== string: value UTF-16LE bytes ==");
printBytes(utf16leBytes);
System.out.println("== string: hessian result ==");
printBytes(result);
}
// -- 输出结果 ------------------------------------------------
== string: D ==
== string: value UTF-8 bytes ==
68 0x44 01000100 D
== string: value UTF-16 bytes ==
-2 0xFE 11111110
-1 0xFF 11111111
0 0x00 00000000
68 0x44 01000100 D
== string: value UTF-16BE bytes ==
0 0x00 00000000
68 0x44 01000100 D
== string: value UTF-16LE bytes ==
68 0x44 01000100 D
0 0x00 00000000
== string: hessian result ==
1 0x01 00000001
68 0x44 01000100 D
== string: Å ==
== string: value UTF-8 bytes ==
-61 0xC3 11000011
-123 0x85 10000101
== string: value UTF-16 bytes ==
-2 0xFE 11111110
-1 0xFF 11111111
0 0x00 00000000
-59 0xC5 11000101
== string: value UTF-16BE bytes ==
0 0x00 00000000
-59 0xC5 11000101
== string: value UTF-16LE bytes ==
-59 0xC5 11000101
0 0x00 00000000
== string: hessian result ==
1 0x01 00000001
-61 0xC3 11000011
-123 0x85 10000101
== string: 瓜 ==
== string: value UTF-8 bytes ==
-25 0xE7 11100111
-109 0x93 10010011
-100 0x9C 10011100
== string: value UTF-16 bytes ==
-2 0xFE 11111110
-1 0xFF 11111111
116 0x74 01110100 t
-36 0xDC 11011100
== string: value UTF-16BE bytes ==
116 0x74 01110100 t
-36 0xDC 11011100
== string: value UTF-16LE bytes ==
-36 0xDC 11011100
116 0x74 01110100 t
== string: hessian result ==
1 0x01 00000001
-25 0xE7 11100111
-109 0x93 10010011
-100 0x9C 10011100
== string: 😂 ==
== string: value UTF-8 bytes ==
-16 0xF0 11110000
-97 0x9F 10011111
-104 0x98 10011000
-126 0x82 10000010
== string: value UTF-16 bytes ==
-2 0xFE 11111110
-1 0xFF 11111111
-40 0xD8 11011000
61 0x3D 00111101 =
-34 0xDE 11011110
2 0x02 00000010
== string: value UTF-16BE bytes ==
-40 0xD8 11011000
61 0x3D 00111101 =
-34 0xDE 11011110
2 0x02 00000010
== string: value UTF-16LE bytes ==
61 0x3D 00111101 =
-40 0xD8 11011000
2 0x02 00000010
-34 0xDE 11011110
== string: hessian result ==
2 0x02 00000010
-19 0xED 11101101
-96 0xA0 10100000
-67 0xBD 10111101
-19 0xED 11101101
-72 0xB8 10111000
-126 0x82 10000010
== string: 👍 ==
== string: value UTF-8 bytes ==
-16 0xF0 11110000
-97 0x9F 10011111
-111 0x91 10010001
-115 0x8D 10001101
== string: value UTF-16 bytes ==
-2 0xFE 11111110
-1 0xFF 11111111
-40 0xD8 11011000
61 0x3D 00111101 =
-36 0xDC 11011100
77 0x4D 01001101 M
== string: value UTF-16BE bytes ==
-40 0xD8 11011000
61 0x3D 00111101 =
-36 0xDC 11011100
77 0x4D 01001101 M
== string: value UTF-16LE bytes ==
61 0x3D 00111101 =
-40 0xD8 11011000
77 0x4D 01001101 M
-36 0xDC 11011100
== string: hessian result ==
2 0x02 00000010
-19 0xED 11101101
-96 0xA0 10100000
-67 0xBD 10111101
-19 0xED 11101101
-79 0xB1 10110001
-115 0x8D 10001101
// 你算对了吗?
D瓜哥
https://www.diguage.com
👍👍👍,老李卖瓜,自卖自夸,😂😂😂这里对于 Unicode 值大于等于 0x800 的字符的处理过程做个总结:
第一步,先将 Unicode 转换成 UTF-16 编码;对于超过 BMP 的字符,UTF-16 会将其拆分成两个字符来处理。由于 Java 内部,
char类型的数据就是使用 UTF-16 编码的,所以,这一步已经提前完成,无需再做处理。第二步,
char值大于等于0x800的char,会将其“值”当做 Unicode 然后转换成“3个字节的UTF-8”。如果是需要两个char表示的字符,则当做两个“Unicode 值”处理,则 会转成两个“3个字节的UTF-8”,就是六个字节。转换过程如下:
Hessian 对字符串的“切割”处理
要测试 Hessian 对字符串的切割,则会使用非常长的字符串,将其编码全部打印出来意义不大。所以,在开始讲解之前,先对之前的工具方法 printBytes 进行适当的改造。
/**
* 打印字节数组
*
* @author D瓜哥 · https://www.diguage.com/
*/
private void printBytes(byte[] result) {
int chunk = 0x8000;
if (0 < result.length && chunk < result.length & result[0] == 'R') {
for (int i = 0; i < result.length; i += (chunk + 3)) {
int j = Math.max(i - 1, 0);
int end = Math.min(i + 4, result.length);
System.out.println(".... " + j + " ~ " + end + " ....");
for (; j < end; j++) {
printByte(result[j]);
}
}
System.out.println("...... " + result.length);
} else {
int max = 10;
for (int i = 0; i < result.length && i < max; i++) {
printByte(result[i]);
}
if (result.length > max) {
System.out.println("...... " + result.length);
}
}
}
/**
* 打印单个字节
*
* @author D瓜哥 · https://www.diguage.com/
*/
private void printByte(byte b) {
String bitx = Integer.toBinaryString(Byte.toUnsignedInt(b));
String zbits = String.format("%8s", bitx).replace(' ', '0');
if (0 <= b) {
System.out.printf("%4d 0x%02X %8s %c %n", b, b, zbits, b);
} else {
System.out.printf("%4d 0x%02X %8s %n", b, b, zbits);
}
}Hessian 中对字符串的处理,根据长度可分不同的几种情况:
长度小于 32 的字符串可以用一个字节长度编码
[x00-x1f]。[x30-x33] b0 <utf8-data>x52 b1 b0 <utf8-data> stringS b1 b0 <utf8-data>字符串被编码成块。
x53(S)表示最终块,x52(R)表示任何非最终块。每个块有一个 16 位无符号整型长度值。
由此可知,Hessian 对不同长度的字符串,在编码时,前置标志符是不一样的。测试代码如下:
/**
* 测试字符串的处理
*
* @author D瓜哥 · https://www.diguage.com/
*/
@Test
public void testString() throws Throwable {
// 0x00~0x31 0~31
// 32~255 的前置标志位是 0x30,然后从 256 开始,每隔 256 个一个标志位。
// 0x30 32~255
// 0x31 256~511
// 0x32 512~767
// 0x33 768~1023
// 之所以这样,是因为使用一个字节来表示“长度”;而 0、1、2、3 保存在前置标志位的末尾。
// 这里又有一个错误:Hessian2Constants.STRING_SHORT_MAX = 0x3ff 最大值是 1023,
// 对应 0x33。所以,0x34 不会出现的。超过 1023 之后,前置标志位就是 S 了。
stringTo("");
// 0~31 之间,直接使用一个字符进行编码
stringTo(getStringByLength("a", 31));
stringTo(getStringByLength("a", 32));
// 32~255 之间,使用一个前缀标志符 0x30(0) + 一个字符进行编码
stringTo(getStringByLength("a", 255));
stringTo(getStringByLength("a", 256));
// 256~511 之间,使用一个前缀标志符 0x31(1) + 一个字符进行编码
stringTo(getStringByLength("a", 511));
stringTo(getStringByLength("a", 512));
// 512~767 之间,使用一个前缀标志符 0x32(2) + 一个字符进行编码
stringTo(getStringByLength("a", 767));
stringTo(getStringByLength("a", 768));
// 768~1023 之间,使用一个前缀标志符 0x33(3) + 一个字符进行编码
stringTo(getStringByLength("a", 1023));
stringTo(getStringByLength("a", 1024));
// 1024~32768 之间,使用一个前缀标志符 0x53(S) + 两个字符进行编码
// 测试字符串分块
// 根据协议中对于字符串的“长度为 0-65535 的字符串”的描述,65535 为分块大小的界限。
// 那么,长度为 65535 应该不分块,a*65535 序列化后,长度应该是 65535 + 3。
// 但是,实际实验的结果为 65535 + 6。那么协议描述有问题。
// stringTo(getStringByLength("a", 65535));
//
// 查看代码,分块相关代码的判断条件是 length > 0x8000,那么分块边界
// 为 0x8000 = 32768。根据输出,跟代码是吻合的。
// 另外,协议中“`x53`(`S`)表示最终块” 的表述不正确!最终块的前置标志符是什么,
// 得看截取完前面的分块之后,剩余的字符的个数。如果大于 1023 才会以 `x53`(`S`)开头。
// 最终块的前置标志符。
stringTo(getStringByLength("a", 32768));
stringTo(getStringByLength("a", 32768 + 1));
stringTo(getStringByLength("a", 32768 + 32));
stringTo(getStringByLength("a", 32768 + 256));
stringTo(getStringByLength("a", 32768 + 512));
stringTo(getStringByLength("a", 32768 + 768));
stringTo(getStringByLength("a", 32768 + 1024));
}
/**
* 根据字符串和长度生成对应长的字符串
*
* @author D瓜哥 · https://www.diguage.com/
*/
private String getStringByLength(String item, int length) {
StringBuilder sb = new StringBuilder(length);
for (int i = 0; i < length; i++) {
sb.append(item);
}
return sb.toString();
}
// -- 输出结果 ------------------------------------------------
== string: ==
== string: length = 0 ==
== string: value UTF-8 bytes ==
== string: value UTF-16BE bytes ==
== string: hessian result ==
0 0x00 00000000
== string: aaaaaaaaaa...31 ==
== string: length = 31 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 31
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 62
== string: hessian result ==
31 0x1F 00011111
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 32
== string: aaaaaaaaaa...32 ==
== string: length = 32 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 32
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 64
== string: hessian result ==
48 0x30 00110000 0
32 0x20 00100000
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 34
== string: aaaaaaaaaa...255 ==
== string: length = 255 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 255
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 510
== string: hessian result ==
48 0x30 00110000 0
-1 0xFF 11111111
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 257
== string: aaaaaaaaaa...256 ==
== string: length = 256 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 256
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 512
== string: hessian result ==
49 0x31 00110001 1
0 0x00 00000000
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 258
== string: aaaaaaaaaa...511 ==
== string: length = 511 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 511
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 1022
== string: hessian result ==
49 0x31 00110001 1
-1 0xFF 11111111
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 513
== string: aaaaaaaaaa...512 ==
== string: length = 512 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 512
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 1024
== string: hessian result ==
50 0x32 00110010 2
0 0x00 00000000
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 514
== string: aaaaaaaaaa...767 ==
== string: length = 767 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 767
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 1534
== string: hessian result ==
50 0x32 00110010 2
-1 0xFF 11111111
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 769
== string: aaaaaaaaaa...768 ==
== string: length = 768 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 768
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 1536
== string: hessian result ==
51 0x33 00110011 3
0 0x00 00000000
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 770
== string: aaaaaaaaaa...1023 ==
== string: length = 1023 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 1023
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 2046
== string: hessian result ==
51 0x33 00110011 3
-1 0xFF 11111111
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 1025
== string: aaaaaaaaaa...1024 ==
== string: length = 1024 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 1024
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 2048
== string: hessian result ==
83 0x53 01010011 S
4 0x04 00000100
0 0x00 00000000
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 1027
== string: aaaaaaaaaa...32768 ==
== string: length = 32768 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 32768
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 65536
== string: hessian result ==
83 0x53 01010011 S
-128 0x80 10000000
0 0x00 00000000
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 32771
== string: aaaaaaaaaa...32769 ==
== string: length = 32769 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 32769
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 65538
== string: hessian result ==
.... 0 ~ 4 ....
82 0x52 01010010 R
-128 0x80 10000000
0 0x00 00000000
97 0x61 01100001 a
.... 32770 ~ 32773 ....
97 0x61 01100001 a
1 0x01 00000001
97 0x61 01100001 a
...... 32773
== string: aaaaaaaaaa...32800 ==
== string: length = 32800 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 32800
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 65600
== string: hessian result ==
.... 0 ~ 4 ....
82 0x52 01010010 R
-128 0x80 10000000
0 0x00 00000000
97 0x61 01100001 a
.... 32770 ~ 32775 ....
97 0x61 01100001 a
48 0x30 00110000 0
32 0x20 00100000
97 0x61 01100001 a
97 0x61 01100001 a
...... 32805
== string: aaaaaaaaaa...33024 ==
== string: length = 33024 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 33024
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 66048
== string: hessian result ==
.... 0 ~ 4 ....
82 0x52 01010010 R
-128 0x80 10000000
0 0x00 00000000
97 0x61 01100001 a
.... 32770 ~ 32775 ....
97 0x61 01100001 a
49 0x31 00110001 1
0 0x00 00000000
97 0x61 01100001 a
97 0x61 01100001 a
...... 33029
== string: aaaaaaaaaa...33280 ==
== string: length = 33280 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 33280
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 66560
== string: hessian result ==
.... 0 ~ 4 ....
82 0x52 01010010 R
-128 0x80 10000000
0 0x00 00000000
97 0x61 01100001 a
.... 32770 ~ 32775 ....
97 0x61 01100001 a
50 0x32 00110010 2
0 0x00 00000000
97 0x61 01100001 a
97 0x61 01100001 a
...... 33285
== string: aaaaaaaaaa...33536 ==
== string: length = 33536 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 33536
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 67072
== string: hessian result ==
.... 0 ~ 4 ....
82 0x52 01010010 R
-128 0x80 10000000
0 0x00 00000000
97 0x61 01100001 a
.... 32770 ~ 32775 ....
97 0x61 01100001 a
51 0x33 00110011 3
0 0x00 00000000
97 0x61 01100001 a
97 0x61 01100001 a
...... 33541
== string: aaaaaaaaaa...33792 ==
== string: length = 33792 ==
== string: value UTF-8 bytes ==
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
97 0x61 01100001 a
...... 33792
== string: value UTF-16BE bytes ==
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
0 0x00 00000000
97 0x61 01100001 a
...... 67584
== string: hessian result ==
.... 0 ~ 4 ....
82 0x52 01010010 R
-128 0x80 10000000
0 0x00 00000000
97 0x61 01100001 a
.... 32770 ~ 32775 ....
97 0x61 01100001 a
83 0x53 01010011 S
4 0x04 00000100
0 0x00 00000000
97 0x61 01100001 a
...... 33798经过上面的测试可以得出:
0~31之间,直接使用一个字符进行编码32~255之间,使用一个前缀标志符0x30(0)+ 一个字符进行编码256~511之间,使用一个前缀标志符0x31(1)+ 一个字符进行编码512~767之间,使用一个前缀标志符0x32(2)+ 一个字符进行编码768~1023之间,使用一个前缀标志符0x33(3)+ 一个字符进行编码1024~32768之间,使用一个前缀标志符0x53(S)+ 两个字符进行编码如果字符串长度大于
32768,则会先截取成长度为32768的一个或多个块,使用一个前缀标志符0x52(R)+ 两个字符进行编码; 不够32768的部分,根据以上条规则进行编码。
有一点需要强调: 32768 也不是一成不变的。根据截取字符串的最后一个 char 来判断。如果最后一个字符是 high surrogate,
即 0xD800 <= Value <= 0xDBFF,则会长度减一,即减少一个 char,来保证后面字符的完整性。
| 关于 “high surrogate” 请问 UTF-16 编码。 |
另外,上文提到的“字符串长度”并不表示我们通常意义的“字”的个数;而是,Java 内部表示字符串的 char 数组的长度。 比如,一个 Emoji 表情就是用两个 char 来表示,则长度为 2。
Hessian 协议中,有两处描述不严谨甚至错误的地方,这里也重点说明一下:
根据协议中对于字符串的“长度为
0-65535的字符串”的描述,65535为分块大小的界限。 那么,长度为65535应该不分块,a*65535序列化后,长度应该是65535 + 3。但是,实际实验的结果为65535 + 6。那么协议描述有问题。查看代码,分块相关代码的判断条件是length > 0x8000,那么分块边界为0x8000 = 32768。根据输出,跟代码是吻合的。协议中“
x53(S)表示最终块” 的表述不正确!最终块的前置标志符是什么, 得看截取完前面的分块之后,剩余的字符的个数。如果大于 1023 才会以x53(S)开头。

再补充一句:D瓜哥以为,对于分块的处理,使用长度为 32767 更为合理。现在使用 32768,长度标志符的编码为 10000000 00000000;而非终块的长度标志符的编码也是 10000000 00000000,有些重叠!使用 32767,则标志符的编码为 `01111111 11111111,这样就可以和非终块的长度标志位区分开。当然,这是个人意见。