Kafka 常见面试题
Kafka 是由 LinkedIn 开发的一个分布式的消息系统,使用 Scala 编写,它以可水平扩展和高吞吐率而被广泛使用。Kafka 本身设计也非常精巧,有很多关键的知识点需要注意。在面试中,也常常被问到。整理篇文章,梳理一下自己的知识点。
架构设计问题
Kafka 整体架构如下:
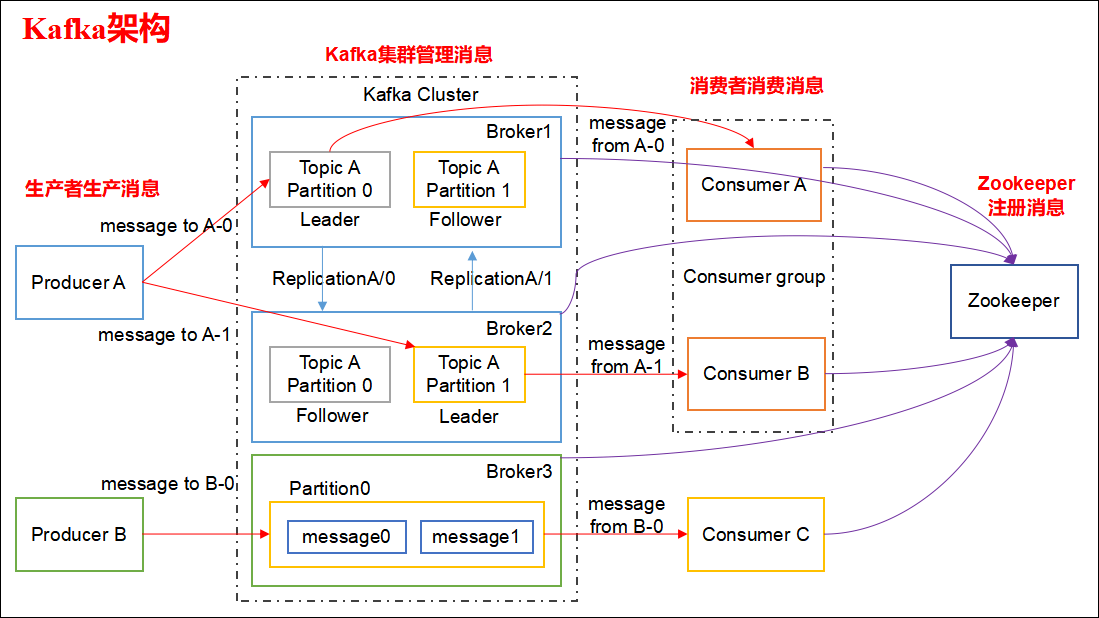
Kafka 架构分为以下几个部分
Producer:消息生产者,就是向 Kafka Broker 发消息的客户端。
Consumer:消息消费者,向 Kafka Broker 取消息的客户端。
Topic:可以理解为一个队列,一个 Topic 又分为一个或多个分区。
Consumer Group:这是 Kafka 用来实现一个 Topic 消息的广播(发给所有的 Consumer)和单播(发给任意一个 Consumer)的手段。一个 Topic 可以有多个 Consumer Group。
Broker:一台 Kafka 服务器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker 可以容纳多个 Topic。
Partition:为了实现扩展性,一个非常大的 Topic 可以分布到多个 Broker上,每个 Partition 是一个有序的队列。Partition 中的每条消息都会被分配一个有序的id(offset)。将消息发给 Consumer,Kafka 只保证按一个 Partition 中的消息的顺序,不保证一个 Topic 的整体(多个 Partition 间)的顺序。
Offset:Kafka 的存储文件都是按照 offset.Kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.Kafka 的文件即可。当然 the first offset 就是 00000000000.Kafka。
Kafka 是如何实现高吞吐率的?
批量异步推送
零拷贝技术
文件分段
服务端顺序写
数据压缩。
批量拉取
Kafka 缺点?
由于是批量发送,数据并非真正的实时;
对于 MQTT 协议不支持;
不支持物联网传感数据直接接入;
仅支持统一分区内消息有序,无法实现全局消息有序;
监控不完善,需要安装插件;
依赖 ZooKeeper 进行元数据管理;
生产者问题
Kafka 如何发送消息?
应用在调用 Kafka 的 API 写消息时,并不是实时发送到服务端的。而是先在本地缓存起来,得到一定的量再发送;或者在一段时间内,还没有达到足够的量,也会发送。另外,API 内置了自动重试,但是也有些错误(比如消息太大)没办法重试,需要单独处理。这个知识点常考,一定要注意。
发送消息 API 有两个:
Future<RecordMetadata> send(ProducerRecord<K, V> record)— 这个 API 没有任何保证,属于 "fire and forget"。所以,它不能用于对消息保证送达的场景下。它底层调用了下面的这个方法,只是第二个方法传递的是null。Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)— 这个方法可以通过Callback callback的回调确切知道消息的处理结果。如果发送失败,也可以自行处理失败。
简述 Kafka 的 ACK 机制.
ack=-1,需要等待 ISR 中所有 follower 都确认收到数据后才算一次发送完成,可靠性最高。
ack=0,生产者将消息发出后就不管了,不需要等待任何返回。
ack=1,只需要经过 leader 成功接收消息的确认就算是发送成功了。
Kafka 中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
拦截器
ProducerInterceptor→ 序列化器Serializer→ 分区器Partitioner。拦截器
ProducerInterceptor— 可以在发送前,对消息做一个统一处理,比如统计发送消息个数。序列化器
Serializer— 把消息进行序列化。分区器
Partitioner— 根据分区算法,对消息进行分区。
Kafka 生产者客户端中使用了几个线程来处理?分别是什么?
2个,主线程和 Sender 线程。主线程负责创建消息,然后通过分区器、序列化器、拦截器作用之后缓存到累加器 RecordAccumulator 中。Sender 线程负责将 RecordAccumulator 中消息发送到 Kafka 中.
消费者问题
“消费组中的消费者个数如果超过 Topic 的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么 hack 的手段?
不正确,通过自定义分区分配策略,可以将一个Consumer指定消费所有Partition。
消费者提交消费位移时提交的是当前消费到的最新消息的 offset 还是 offset+1 ?
offset+1
Rebalance 的弊端是什么呢?
Rebalance 影响 Consumer 端 TPS。在 Rebalance 期间,Consumer 会停下手头的事情,什么也干不了。
Rebalance 很慢。一个极端案例:Group 下有几百个 Consumer 实例,Rebalance 一次要几个小时。
Rebalance 效率不高。当前 Kafka 的设计机制决定了每次 Rebalance 时,Group 下的所有成员都要参与进来,而且通常不会考虑局部性原理。
什么情况下会发生 Rebalance?
组成员数量发生变化,增加 Consumer 实例或者 Consumer 实例心跳检查(
session.timeout.ms)失败也会引起 Rebalance。订阅主题数量发生变化,这种情况一般出现在使用通配符订阅主题的情况。
订阅主题的分区数发生变化,增加分区时。
Rebalance 有什么新变化吗?
在 Kafka 2.5.0 稳定版中,增加了“Kafka Consumer 支持增量再平衡(Incremental rebalance)”特性。incremental 协议允许消费者在重新平衡事件期间保留其分区,从而尽量减少消费者组成员之间的分区迁移。因此,通过 scaling out/down 操作触发的端到端重新平衡时间更短,这有利于重量级、有状态的消费者,比如 Kafka Streams 应用程序。
有哪些情形会造成重复消费?
消费者消费后没有 commit offset(程序崩溃/强行kill/消费耗时/自动提交偏移情况下unscrible)
哪些情景下会造成消息遗漏消费?
消费者没有处理完消息就提交 offset(自动提交偏移,未处理情况下程序异常结束)。
KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?在每个线程中新建一个
KafkaConsumer单线程创建
KafkaConsumer,多个处理线程处理消息(难点在于是否要考虑消息顺序性,offset的提交方式)
简述消费者与消费组之间的关系。
消费者从属与消费组,消费偏移以消费组为单位。每个消费组可以独立消费主题的所有数据,同一消费组内消费者共同消费主题数据,每个分区只能被同一消费组内一个消费者消费。
Kafka 消费者是否可以消费指定分区消息?
Kafa Consumer 消费消息时,向 Broker 发出 fetch 请求去消费特定分区的消息,Consumer 指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer 拥有了 offset 的控制权,可以向后回滚去重新消费之前的消息。
服务端问题
Kafka 中的 ISR、OSR、AR 又代表什么?ISR 的伸缩又指什么?
ISR:In-Sync Replicas 副本同步队列
OSR:Out-of-Sync Replicas
AR:Assigned Replicas 所有副本
ISR 是由 leader 维护,follower 从 leader 同步数据有一些延迟(包括延迟时间
replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本 0.10.x 中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把 follower 剔除出 ISR, 存入 OSR(Outof-Sync Replicas)列表,新加入的 follower 也会先存放在 OSR 中。AR = ISR + OSR。Kafka 目前有那些内部 Topic,它们都有什么特征?各自的作用又是什么?
__Consumer_offsets以下划线开头,保存消费组的偏移。从 Kafka 2.5.0 正式版开始,Kafka 准备去除对 ZooKeeper 的依赖,这个工作可能要持续几个版本才能完成。到时,应该也会有新的 Topic。
Kafka 中的 HW、LEO、LSO、LW 等分别代表什么?
HW:High Watermark 高水位,严格来说,它表示的就是位置信息,即位移(offset)。取一个 Partition 对应的 ISR 中最小的 LEO 作为HW,Consumer 最多只能消费到 HW 所在的位置上一条信息。
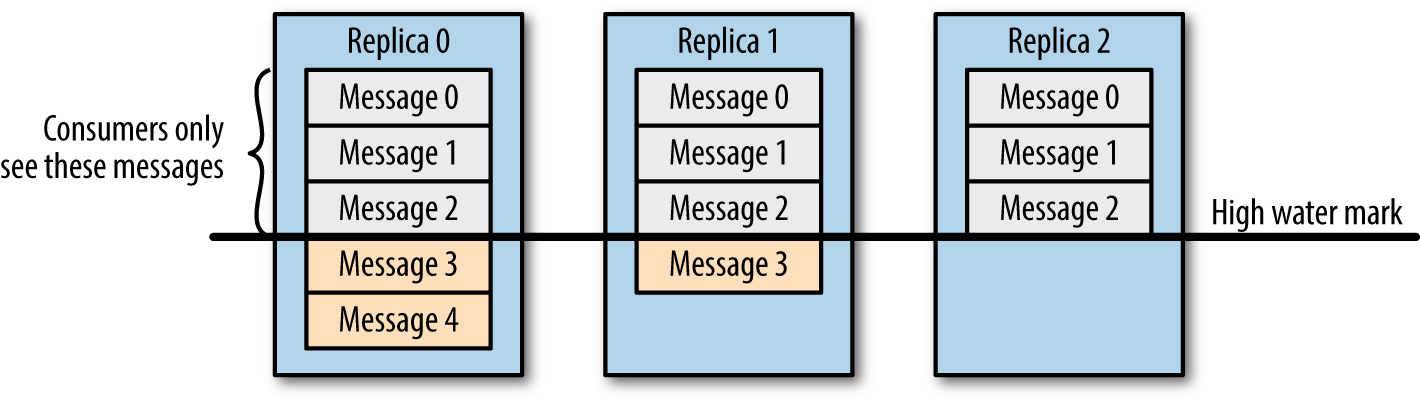 图 2. High Water Mark
图 2. High Water MarkLEO:LogEndOffset 当前日志文件中下一条待写信息的 offset。
HW/LEO 这两个都是指最后一条的下一条的位置而不是指最后一条的位置。
LSO:LastStableOffset 对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同
LW:Low Watermark 低水位, 代表 AR 集合中最小的 logStartOffset 值
优先副本是什么?它有什么特殊的作用?
优先副本会是默认的 leader 副本,发生 leader 变化时重选举会优先选择优先副本作为 leader。
简述 Kafka 的日志目录结构。
每个Partition一个文件夹,包含四类文件
.index.log.timeindexleader-epoch-checkpoint。.index.log和.timeindex三个文件成对出现,前缀为上一个segment的最后一个消息的偏移。.log文件中保存了所有的消息;.index文件中保存了稀疏的相对偏移的索引;.timeindex保存的则是时间索引;leader-epoch-checkpoint中保存了每一任 leader 开始写入消息时的 offset,会定时更新,follower 被选为 leader 时会根据这个确定哪些消息可用。
Kafka 分区的目的?
分区对于 Kafka 集群的好处是:实现负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
实际应用问题
Kafka 的用途有哪些?使用场景如何?
日志收集:一个公司用 Kafka 收集各种服务的 log,通过 Kafka 以统一接口服务的方式开放给各种 Consumer,例如 Hadoop、HBase、Solr 等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka 经常被用来记录 Web 用户或者 APP 用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到 Kafka 的 Topic 中,然后订阅者通过订阅这些 Topic 来做实时的监控分析,或者装载到 Hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka 也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如 Spark Streaming 和 Flink
Kafka 如何保证数据的一致性?
这是一个全局性问题需要需要从如下几个方面来考虑:
发送端要是用
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)方法来发送消息。如果出现错误,可以通过代码来处理错误。服务端,要设置
ack=-1,分区要最少三副本,来保证数据的不会丢失。消费端,消费是接上一次消费的 offset 开始消费;消费成功后,再同步提交 offset。
业务方,要保证接口的幂等性,防止重复消费消息带来的数据不一致性。
| Kafka 问题还远远不止这些,后续再慢慢完善。 |