前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
在上一篇文章 Hessian 源码分析(Java) 对 Hessian 的 Java 实现做了一个概要的分析,对处理流程以及整体架构做了一个简单的分析。接下来,回到主题,继续来解释 Hessian 序列化协议。这篇文章,我们来重点分析一下数组与集合相关的操作。
基础工具方法 基础工具方法就不再赘述,请直接参考 Hessian 协议解释与实战(一):基础工具方法 中提到的几个方法。
对打印字符的工具做一下改造:
前面通过几篇文章,解释并实践了一下 Hessian 的序列化协议。文章目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
该系列第四篇文章准备详细介绍一下 Hessian 对对象、链表以及 Map 等处理。但是,越调试代码,越发觉得应该先对 Hessian 的实现做一个源码分析。于是,就有了本文。
这里有几点需要声明一下:
在上面“解释与实战”系列文章中提到的代码就不再重复说明。
通过“解释与实战”系列文章,大家应该可以领略到,处理序列化有大量的细节。但是,本文并不打算涉及。本文重点是介绍 Hessian 的 Java 实现的架构蓝图。相当于给指明一条路,沿着这条路,大家就可以探索 Hessian 的各种细节。
前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
在上一篇文章 Hessian 协议解释与实战(二):长整型、二进制数据与 Null 中研究了长整型、二进制数据与 null 等三种数据类型的处理方式。接下来,我们再来介绍字符串的处理情况。
前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
在上一篇文章 Hessian 协议解释与实战(一) 中研究了布尔型数据、日期类型、浮点类型数据、整数类型数据等四种数据类型的处理方式。接下来,我们再来介绍长整数类型数据、二进制数据和 null 的处理情况。
前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。
目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
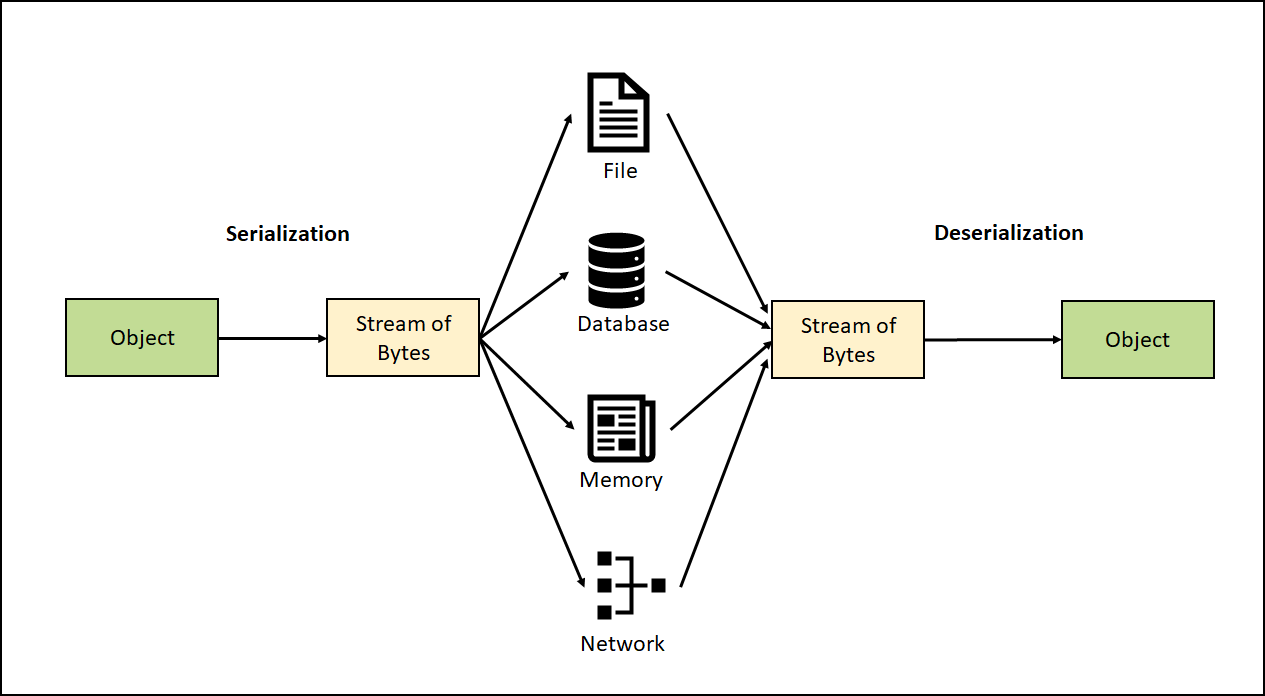
基础工具方法 Hessian 序列化之后的数据,都是字节数组,为了方便查看字节数组的二进制形式和十六进制形式,在正式开始之前,先介绍一下期间用到的辅助工具方法。闲言少叙,直接上代码:
/** * 创建 Hessian2Output 对象,以便用于序列化 * * @author D瓜哥 · https://www.
公司在微服务系统中,序列化协议大多数使用 MessagePack。但是,由于 MessagePack 设计限制,导致微服务接口在增减参数时,只能在最后操作。但是,由于个人操作,难免失误,结果造成因为增减字段导致的事故层出不穷。最近,一些条件成熟,准备推动部门将序列化协议切换到 Hessian。
原以为,切换到 Hessian 就可以万事大吉。但是,在和同事的沟通中发现,同事反馈,Hessian 本身也有一些限制。为了对 Hessian 有一个更深入的了解,干脆就把 Hessian 序列化协议读一遍。看协议,文字不多,干脆就把协议完整翻译一遍。闲言少叙,正文开始。
Hessian 2.0 序列化协议 协议解释 针对该协议有很多言语不详,甚至模糊不清之处,专门做了一些解释和实践,叙述系列文章,用于辅助消化理解。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
加入公司以来,参与了很多个项目的开发维护;也排查处理过很多线上问题;为了写 Mock 测试,也专门去日志系统上扒拉过不少日志等等。在整个过程中,对日志的认识有了不少更深刻的认识和体会。也发现不少问题。这里先从存在的问题展开论述。
日志存在的问题 从个人的眼光上来看,当前的系统存在如下问题:
必要日志没有打印出来,导致在追踪问题或测试代码时,带来不必要的麻烦。比如查看一个接口的返回值用于 Mock 测试;再比如 RPC 调用报错,返回值以及错误信息没有打印到日志中,不知道具体错误原因是什么。
日志抽取中日志路径配置错误,导致日志重复收集,带来不必要的处理和存储成本。
日志代码不规范,导致不必要的性能消耗;或者大促时,日志降级不生效。
日志框架繁多,造成造成冲突,遗漏部分日志。
日志配置不规范,不利于日志的采集和清洗。
日志和调用链路物理隔离,查看一个请求的整个调用链路上的日志非常不方便,不利于问题的快速排查和定位。
大家的系统中,存在什么样的日志问题?欢迎留言交流讨论。
针对这些问题,我觉得有些地方值得发力一下。然后,做了一些探索,总结一下,以备后续使用。
日志最佳实践探索 对于日志的使用,相信所有的开发人员都比较清楚,网上也有大量资料,相关日志框架的官方文档,也写的非常详尽,这里就不再赘述。
本文从一个角度对日志规范进行探究:在排查问题时,能否通过日志来尽快地了解系统运行状态,定位问题原因?另外,由于 Java 的日志框架特别多,有一些比较容易迷惑的问题,尝试做出一点总结。
系统运行后,不严格地说,再去观察系统运行状态,就类似于在黑夜中行走。此时,向你扔过来一块板砖🧱,那么,事后如何追责呢?
请问:你能否成功躲开这块叫做 Bug 的板砖🧱?
日志用来记录用户操作、系统运行状态等,是一个系统的重要组成部分。然而,由于日志通常不属于系统的核心功能,但是在日志对于排查问题,有无可替代的作用,理应得到所有开发人员的重视(不重视,怎么甩锅?!)!
If dog is a man’s best friend, logs are software engineer’s best friend.
— Geshan Manandhar Logging best practices 好的日志可以帮助系统的开发和运维人员:
了解线上系统的运行状态
快速准确定位线上问题
发现系统瓶颈
预警系统潜在风险
挖掘产品最大价值
可以将一个流程完整串起来(比如orderId)
……
不好的日志导致:
对系统的运行状态一知半解,甚至一无所知
系统出现问题无法定位,或者需要花费巨大的时间和精力
无法发现系统瓶颈,不知优化从何做起
无法基于日志对系统运行过程中的错误和潜在风险进行监控和报警
对挖掘用户行为和提升产品价值毫无帮助
……
日志从功能来说,可分为诊断日志、统计日志、审计日志。统计日志一般由运维组负责;而审计日志,一般是需要通过代码来实现。这里重点来说说诊断日志。
诊断日志, 典型的有:
请求入口和出口
外部服务调用和返回
资源消耗操作: 如读写文件等
容错行为: 如云硬盘的副本修复操作
在上一篇文章 分布式锁之 Apache Curator InterProcessMutex 中介绍了基于 ZooKeeper 实现的互斥锁。除此之外,还可以实现读写锁。这篇文章就来简要介绍一下 InterProcessReadWriteLock 的实现原理。
老规矩,先看看类的注释:
/** * <p> * A re-entrant read/write mutex that works across JVMs. Uses Zookeeper to hold the lock. All processes * in all JVMs that use the same lock path will achieve an inter-process critical section. Further, this mutex is * "fair" - each user will get the mutex in the order requested (from ZK's point of view). * </p> * * <p> * A read write lock maintains a pair of associated locks, one for read-only operations and one * for writing.
对分布式锁耳熟能详。不过,一直关注的是基于 Redis 实现的分布式锁。知道 ZooKeeper 也可以实现分布式锁。但是,原来的想法是把 Redis 那个思路切换到 ZooKeeper 上来实现就好。今天了解到 Apache Curator 内置了分布式锁的实现: InterProcessMutex。查看了一下源码实现,发现跟基于 Redis 实现的源码相比,在思路上还是有很大不同的。所以,特别作文记录一下。
先来看一下,整体流程:
结合流程图和源码,加锁的过程是这样的:
先判断本地是否有锁数据,如果有则对锁定次数自增一下,然后返回 true;
如果没有锁数据,则尝试获取锁:
在指定路径下创建临时顺序节点
获取指定路径下,所有节点,检查自身是否是序号最小的节点:
如果自身序号最小,则获得锁;否则
如果自身不是序号最小的节点,则通过 while 自旋 + wait(times) 不断尝试获取锁,直到成功。
获得锁后,把锁信息缓存在本地 ConcurrentMap<Thread, LockData> threadData 变量中,方便计算重入。
在 ZooKeeper 中的结构大致如下:
下面我们逐个方法进行分析说明。先来看一下 InterProcessMutex 的注释:
/** * A re-entrant mutex that works across JVMs. Uses Zookeeper to hold the lock. All processes in all JVMs that * use the same lock path will achieve an inter-process critical section.
今天是世界读书日,各种人都在推荐书单。D瓜哥也凑个热闹,水一篇文章,推荐一些书籍。
在前一段时间,D瓜哥已经写了一个书单: 推荐几本 Java 并发编程的书。为了避免重复,上一个书单中推荐过的书籍,这次就不再重复推荐了。
每年十二个月,D瓜哥就推荐 12 本书,每个月读一本想必压力也不算大。
如何阅读一本书? D瓜哥在年初的时候,刚刚再次重读了这本书。而且,还写了一篇读书笔记: 《如何阅读一本书?》之读书笔记。
如果喜欢读书,那么这本书绝对应该是首先阅读的第一本书。一句话总结一下:用检视阅读的方法来快速筛选出你关注主题的书籍;用分析阅读的方法来吸收一本书的精华;用主题阅读的办法来对多本同一主题的书去伪存真,加工再输出。
远见 D瓜哥在去年年末写的年终总结 “告别 2019,迎接 2020” 中提到了这本书。考虑这本书的实用性和对自身发展的指导意义,所以决定再次推荐这本书。
在这本书中,作者将职业生涯分为:强势开局、聚焦长板和实现持续的影响力三个阶段。
在强势开局阶段,就像要开始一个汽车拉力赛,要努力加添燃料。
在聚焦长板阶段,要努力提高自己的核心竞争力,创造自己的制高点。
在实现持续的影响力阶段,则要优化长尾效应,让自己持续保持领先。
对于职业生涯有追求的小伙伴,尤其是在读大学生,一定要去尽早认真读一读这本书。
思考,快与慢 这是一本有关心理学方面的书籍。作者丹尼尔•卡尼曼因其与阿莫斯•特沃斯基在决策制定上的研究而荣获了 2002 年度的诺贝尔经济学奖。所以,这本书质量上肯定是有保证的。
这本书主要是介绍认知心理学的。作者在书中,把人的认知分为系统一和系统二。系统一是那种不需要思考的,已经固化在我们基因中的反应,比如看见危险会跑路等;而系统二,则是需要深入思考才能有所收获的事情,比如在新税法下,计算个人应该缴纳的个人所得税。两个系统相辅相成,时刻影响着我们的生活,但我们却有些熟视无睹。
穷查理宝典 提起查理·芒格,也许有些人不知道是谁。(看这篇文章的读者估计都了解)但是,他的搭档估计是人尽皆知,那就是世界股神沃伦·巴菲特。
虽然这本书不是查理·芒格书写的,里面的精华部分,却都是查理的演讲稿。通过这些演讲,你可以看到一个睿智的老人,如何在循循善诱地向你传授他的思维方法。查理给我们介绍了他的思维模型:逆向思维,多元思维模型,打造自己的核心圈,避免嫉妒效应,内部积分卡(用我们古人的话说就是反求诸己)等等。
社会性动物 D瓜哥是去年开始读这本书的,非常抱歉目前还没有读完。
这本书是讲述社会心理学的,讲述在这个社会中,人与人之间是如何相互影响的。举一个典型的例子:你思考过吗,什么样的广告最能打动你吗?
事实 比尔·盖茨也推荐了这本书。我也是最近刚刚开始读这本书。还没有读完。就不做过多评价了。用一个问题,勾引一下你的兴趣:
问题:在全世界所有的低收入国家里面,有多少百分比的女孩能够上完小学?
选项:A. 20% B. 40% C. 60%
想知道答案,就快点去读这本书吧。
最近更新:D瓜哥终于把这本书读完了:https://www.diguage.com/post/factfulness/[《事实》之读书笔记^]。
人类简史 坦白讲,这本书D瓜哥才读了一半。但是,作者最近发表的一篇文章: 尤瓦尔·赫拉利《冠状病毒之后的世界》,一个史学家站在历史发展的角度去看待疫情对世界发展的影响。由此可对赫拉利的思想窥得一斑。那么,如果感兴趣,他的成名大作《人类简史》就不得不读了。
最近因为疫情影响,在网上看到各种五毛的无脑言论,怼天怼地,仿佛中国要征服世界,征服宇宙一样,真是让人呵呵…
未来几十年时间里,中国未来寻求自身发展,还需要融入到整个世界经济中,在全世界产业链中,力争上游,占领高附加值的产业,比如芯片,5G,大飞机等等。怼这个,怼那个,只能让自己像二战时期的纳粹德国和日本,让自己四面树敌,最后被全世界群殴。
上帝掷骰子吗? 这是D瓜哥看过的,最好看的科普书,没有之一。
你知道爱因斯坦因为发表相对论,革了物理学的命;但是你知道吗?爱因斯坦也因为自己的顽固守旧阻碍过量子物理的发展。你知道普朗克首次提出量子的概念;但是,你了解吗?普朗克却是非常坚决地反对量子物理的发展。你了解薛定谔的猫到底是怎么回事吗?这些料都可以在这本书中读到。
作者通过各种各样的故事展示了量子物理学从无到有,颠覆整个经典物理,然后又重塑整个现代物理的过程。整个故事可谓波澜壮阔,跌宕起伏。
另外,从这本书中,我希望大家能读出科学的味道。曾经跟一个朋友在讨论,到底什么是科学?我举两个例子来说明:
关于光本质的三次论战 现在,上过高中物理的人都了解,光具有波粒二象性。说得更直白一些,光即是波,也是粒子。围绕光到底是波,还是粒子在历史上,曾经有过三次论战,参与论战的也不乏大家耳熟能详的物理大咖。
第一次的主角是牛顿牛爵爷,通过观察光的直线传播和反射现象,牛顿将光解释为粒子。考虑到牛顿在当时已经是成绩斐然的世界知名物理学家,他的观点在当时得到了广泛的认可。这是第一次论战。
第二次论战的主角是托马斯·杨,这位主角想必学过高中物理的童鞋,想必对双缝干涉实验都有印象。双缝干涉实验是高中物理中非常重要的一个实验,而且操作也很简单。双缝干涉实验就是托马斯·杨发明的。托马斯·杨完成了双缝干涉实验,有力地证明了光的波动性质。然后,大家开始普遍接受光的波动性学说。
你以为这就完了吗?然而并没有,最后踢出临门一脚的是又一个大名鼎鼎的物理学家:爱因斯坦。1905年,爱因斯坦发表论文,对于光电效应给出解释。他把光解释为即是波,也是粒子。至此,这个长达近三百年的争论才得以盖棺论定。爱因斯坦也因为这篇论文,获得了 1921 年度的诺贝尔物理学奖。
牛顿的经典力学 学过初中物理的童鞋,相关对牛顿运动三定理都很了解。从 1687 年,牛顿发表《自然哲学的数学原理》,在书中详细阐述了牛顿运动三定律。至此,两百多年时间里,《自然哲学的数学原理》几乎奠定了经典物理的基础。可谓无往不胜。
但是,在计算水星轨道时,总是出现微小的偏差。物理学家不断尝试来解决这个问题,却一直未能如愿。直道 1915 年爱因斯坦发表广义相对论,才正确地解释了水星近日点的反常进动。后来,经过广义相对论的进一步的发展,人们发现,牛顿运动定律只是在低速情况下,广义相对论的特例。