
前面系统研究了 Hessian 序列化协议。并以此为契机,顺带实例对比了 Hessian、MessagePack 和 JSON 的序列化。早在 2012 年,Martin Kleppmann 就写了一篇文章 《Schema evolution in Avro, Protocol Buffers and Thrift》,也是基于实例,对比了 Avro、ProtoBuf、Thrift 的差别。现在翻译出来,方便做系列研究。
整个“序列化系列”目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。

8·19中国医师节
致敬守护健康的白衣天使
虽然我一直挺健康,但我与医生的故事有好多。按时间顺序,挑选几个来说一说。
早在 2018 年,由于智齿斜长,顶住最后大牙,担心影响到大牙的健康,就到北京大学口腔医院魏公村总院,做智齿拔除手术。由于去排队时间较晚,就被分配了一个急诊号,不知道医生是何许人也。拍片做完检查,医生说我上下有两个智齿,可以考虑一起拔除。麻药敲击拔牙,一气呵成。医生说,你可以走啦。我疑问,不是拔两颗吗?怎么只拔了一颗?医生说,两颗都拔啦。没想到这么迅速。实在是太专业啦!这名医生叫郭华秋。
在 2019 年,在盆友圈看到一个纪录片《医者·脊梁》,认识了一个医生,在业余时间,利用自己的专业知识,深入偏远地区,为这些偏远地区免费义诊,并且建立了一个基金会,为需要手术的脊柱侧弯患者承担必要的费用。经过短暂思考后就决定,要为这个基金会捐款,让他们去救助更多的人。初步定在每年六一儿童节这天,每年捐一千块钱,连续捐十年。这家基金会叫北京海鹰脊柱健康公益基金会。这名医生叫刘海鹰。(他是我的安阳老乡,也是我的大学师兄。真是荣幸之至!)放两张盆友圈截图:
Figure 1. 2018年捐款 Figure 2. 2022年捐款 2020年,一场突如其来的疫情,让很多很多医护工作者舍小家为大家,用自己的臂膀组建了守护大家健康的卫生长城。这些医生和护士叫中国医护人员。
感谢他们的付出,感谢他们的辛劳,也感谢他们的专业。有感于此,我在2021年初,就请我认识的每一位医护朋友吃一顿饭。可惜到现在为止,还没有成行。以后有机会一起吃饭的话,希望医护朋友不要可以客气,给我一个表达感激的机会。
Figure 3. 向医护人员致敬 这是公众号的一篇文章。昨天早晨出门吃早餐,刷朋友圈才知道昨天是医师节。在地铁上写了这篇文章。本来是昨天群发的。由于没有想尝试一次群发多篇文章,就在手机APP上先发表了附加的文章,以为只是发布而不群发。结果,搞了个乌龙,直接群发了,也没办法撤销群发。所以,这篇文章只能今天发表了。

前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。
目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
未完待续,敬请继续关注 "地瓜哥"博客网。
本文用实际来对比一下 JSON、Hessian 和 MessagePack 的区别。
模型 package com.diguage; import java.math.BigDecimal; import java.util.Date; /** * 用户 * * @author D瓜哥 · https://www.

前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
在上一篇文章 Hessian 协议解释与实战(四):数组与集合 中研究了数组和集合的处理方式。接下来介绍对象和映射的处理。
基础工具方法 基础工具方法就不再赘述,请直接参考 Hessian 协议解释与实战(一):基础工具方法 中提到的几个方法。
前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
在上一篇文章 Hessian 源码分析(Java) 对 Hessian 的 Java 实现做了一个概要的分析,对处理流程以及整体架构做了一个简单的分析。接下来,回到主题,继续来解释 Hessian 序列化协议。这篇文章,我们来重点分析一下数组与集合相关的操作。
基础工具方法 基础工具方法就不再赘述,请直接参考 Hessian 协议解释与实战(一):基础工具方法 中提到的几个方法。
对打印字符的工具做一下改造:

前面通过几篇文章,解释并实践了一下 Hessian 的序列化协议。文章目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
该系列第四篇文章准备详细介绍一下 Hessian 对对象、链表以及 Map 等处理。但是,越调试代码,越发觉得应该先对 Hessian 的实现做一个源码分析。于是,就有了本文。
这里有几点需要声明一下:
在上面“解释与实战”系列文章中提到的代码就不再重复说明。
通过“解释与实战”系列文章,大家应该可以领略到,处理序列化有大量的细节。但是,本文并不打算涉及。本文重点是介绍 Hessian 的 Java 实现的架构蓝图。相当于给指明一条路,沿着这条路,大家就可以探索 Hessian 的各种细节。
前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
在上一篇文章 Hessian 协议解释与实战(二):长整型、二进制数据与 Null 中研究了长整型、二进制数据与 null 等三种数据类型的处理方式。接下来,我们再来介绍字符串的处理情况。
前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
在上一篇文章 Hessian 协议解释与实战(一) 中研究了布尔型数据、日期类型、浮点类型数据、整数类型数据等四种数据类型的处理方式。接下来,我们再来介绍长整数类型数据、二进制数据和 null 的处理情况。
前段时间,翻译了 Hessian 2.0 的序列化协议,发布在了 Hessian 2.0 序列化协议(中文版)。但是,其中有很多言语不详之处。所以,接下来会用几篇文章来详细解释并实践一下 Hessian 序列化协议,以求做到知其然知其所以然。
目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。
基础工具方法 Hessian 序列化之后的数据,都是字节数组,为了方便查看字节数组的二进制形式和十六进制形式,在正式开始之前,先介绍一下期间用到的辅助工具方法。闲言少叙,直接上代码:
/** * 创建 Hessian2Output 对象,以便用于序列化 * * @author D瓜哥 · https://www.
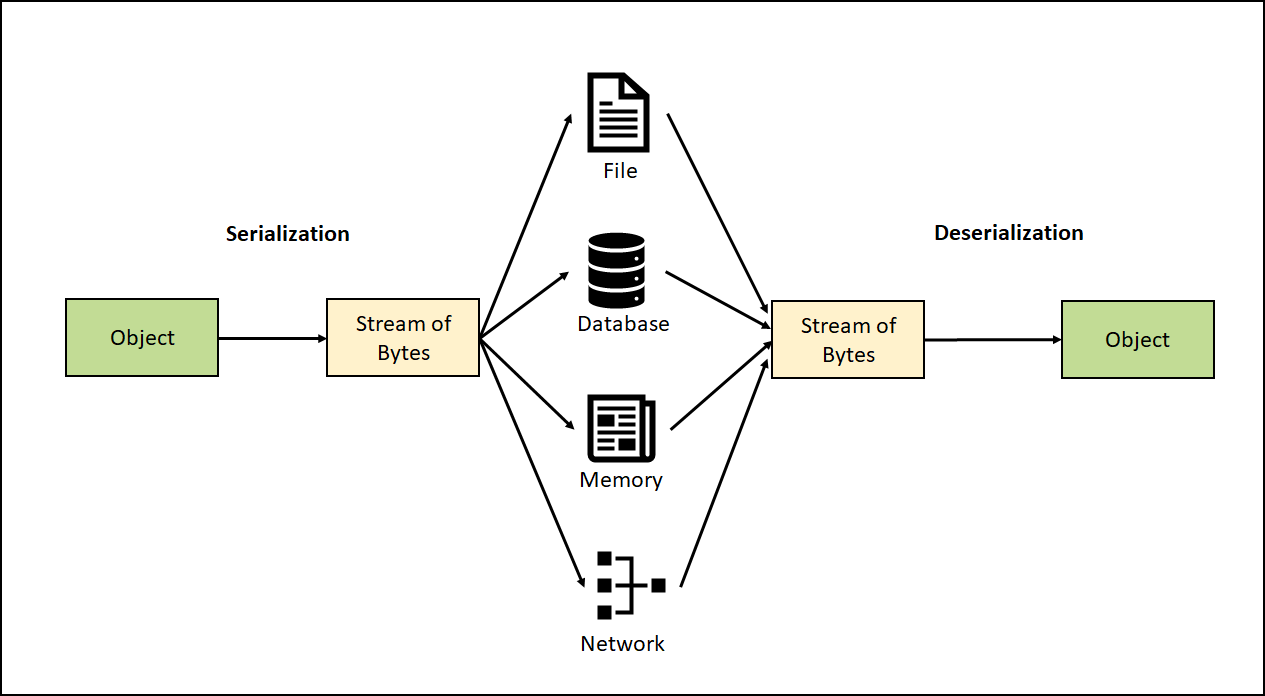
公司在微服务系统中,序列化协议大多数使用 MessagePack。但是,由于 MessagePack 设计限制,导致微服务接口在增减参数时,只能在最后操作。但是,由于个人操作,难免失误,结果造成因为增减字段导致的事故层出不穷。最近,一些条件成熟,准备推动部门将序列化协议切换到 Hessian。
原以为,切换到 Hessian 就可以万事大吉。但是,在和同事的沟通中发现,同事反馈,Hessian 本身也有一些限制。为了对 Hessian 有一个更深入的了解,干脆就把 Hessian 序列化协议读一遍。看协议,文字不多,干脆就把协议完整翻译一遍。闲言少叙,正文开始。
Hessian 2.0 序列化协议 协议解释 针对该协议有很多言语不详,甚至模糊不清之处,专门做了一些解释和实践,叙述系列文章,用于辅助消化理解。目录如下:
Hessian 2.0 序列化协议(中文版) — Hessian 序列化协议的中文翻译版。根据后面的“协议解释与实战”系列文章,增加了协议内容错误提示。
Hessian 协议解释与实战(一):布尔、日期、浮点数与整数 — 介绍布尔型数据、日期类型、浮点类型数据和整数类型数据等四种类型的数据的处理。
Hessian 协议解释与实战(二):长整型、二进制数据与 Null — 介绍长整数类型数据、二进制数据和 null 等三种类型的数据的处理。
Hessian 协议解释与实战(三):字符串 — 专门介绍了关于字符串的处理。由于字符串需要铺垫的基础知识比较多,处理细节也有繁琐,所以单独成篇来介绍。
Hessian 源码分析(Java) — 开始第四篇分析之前,先来介绍一下 Hessian 的源码实现。方便后续展开说明。
Hessian 协议解释与实战(四):数组与集合 — 铺垫了一些关于实例对象的处理,重点介绍关于数组和集合的相关处理。
Hessian 协议解释与实战(五):对象与映射 — 重点介绍关于对象与映射的相关处理。
Hessian、Msgpack 和 JSON 实例对比 — 用实例对比 JSON、Hessian 和 MessagePack 的区别。
Avro、ProtoBuf、Thrift 的模式演进之路 — 翻译的 Martin Kleppmann 的文章,重点对比了 Avro、ProtoBuf、Thrift 的序列化处理思路。