AWK 简介

这周需要处理一个日志文件,有一次体会到 AWK 强大和方便,但也认识到自己对 AWK 了解的粗浅。所以,写篇文章再深入学习一下。
根据维基百科显示,AWK 于二十世纪七十年代在 Bell Labs 创建;其名字来源于三位创始人: Alfred Aho、Peter Weinberger and Brian Kernighan。AWK 是一个现在几乎每台 Linux 机器上都会有这个命令。
AWK 是一种领域专用语言,专用设计用于文本处理,常用于提取文本或者生成报告。 AWK 也像 Shell 一样,方言和实现众多。D瓜哥这里选择最常用的 GNU AWK 实现。
AWK 是以行为单位来处理文本的。它不仅仅是一个命令行,而且是一门语言。
先展示一下我们的实例程序:
$ cat employee.txt
ajay manager account 45000
sunil clerk account 25000
varun manager sales 50000
amit manager account 47000
tarun peon sales 15000
deepak clerk sales 23000
sunil peon sales 13000
satvik director purchase 80000AWK 的基本用法如下:
# ① 基本格式
$ awk 动作 文件名
# ② 标准 I/O 格式
$ cat 文件名 | awk 动作先给大家来个 Hello World:
$ awk '{print}' employee.txt
ajay manager account 45000
sunil clerk account 25000
varun manager sales 50000
amit manager account 47000
tarun peon sales 15000
deepak clerk sales 23000
sunil peon sales 13000
satvik director purchase 80000当然,也可以这样写:
$ cat employee.txt | awk '{print}'
ajay manager account 45000
sunil clerk account 25000
varun manager sales 50000
amit manager account 47000
tarun peon sales 15000
deepak clerk sales 23000
sunil peon sales 13000
satvik director purchase 80000另外,需要特别说明一点,可以指定分隔符,例如:
$ echo "root:x:0:0:root:/root:/bin/bash" | awk -F: '{print $1, $NF}'
root /bin/bash还可以指定多个分隔符:
$ echo "root:x:0:0:root:/root:/bin/bash" | awk -F[:/] '{print $1, $NF}'
root bash上文提到了,AWK 是以行(默认分隔符是换行符,也可以指定不同字符)为单位来进行处理文本的。默认情况下, AWK 会以空格或者制表符来分割行,以 $$1、 $2、 $3 等来表示第一、二、三列,以此类推。另外一点需要注意 $0 比较特殊,它表示整行。所以,完整打印文件也可以这样
$ awk '{print $0}' employee.txt
ajay manager account 45000
sunil clerk account 25000
varun manager sales 50000
amit manager account 47000
tarun peon sales 15000
deepak clerk sales 23000
sunil peon sales 13000
satvik director purchase 80000输出第一列和第三列可以这样写:
$ awk '{print $1, $3}' employee.txt
ajay account
sunil account
varun sales
amit account
tarun sales
deepak sales
sunil sales
satvik purchase在 print 命令中,如果需要原样输出,则需要使用双引号括起来。所以,默认分隔符是空格,如果需要指定分隔符可以这样写:
$ awk '{print $1 ", " $3}' employee.txt
ajay, account
sunil, account
varun, sales
amit, account
tarun, sales
deepak, sales
sunil, sales
satvik, purchase除了上面变量外,AWK 还内置了其他很多变量:
FILENAME:当前文件名NF:表示当前行有多少个字段,那么$NF就表示最后一行;$(NF-1)则表示倒数第二列。NR:表示当前行数;FS:字段分隔符,默认是空格和制表符。RS:行分隔符,用于分割每一行,默认是换行符。OFS:输出字段的分隔符,用于打印时分隔字段,默认为空格。ORS:输出记录的分隔符,用于打印时分隔记录,默认为换行符。OFMT:数字输出的格式,默认为%.6g。
我们输出一下当前行号以及每行的第一列和最后一列:
$ awk '{print NR, $1, $NF}' employee.txt (1)
1 ajay 45000
2 sunil 25000
3 varun 50000
4 amit 47000
5 tarun 15000
6 deepak 23000
7 sunil 13000
8 satvik 80000| 1 | 注意: NR 前面不能加 $ 符。 |
输出有些凌乱,可以使用 AWK 的格式化输出:
$ awk '{printf "%2d %-7s %-6d\n", NR, $1, $NF}' employee.txt
1 ajay 45000
2 sunil 25000
3 varun 50000
4 amit 47000
5 tarun 15000
6 deepak 23000
7 sunil 13000
8 satvik 80000我们这里用到了 %d、 %s 格式化符。 AWK 内置的格式化符如下:
%a, %A— 打印浮点数。%c— 将数字以字符打印。%d, %i— 打印整数。%e, %E— 用科学计算法打印数字。%f— 打印浮点数;%F— 类似%f,只是无穷大或者去穷小以大写字母打印。%g, %G— 使用科学计数法打印数字;%G使用E代替e。%o— 打印无符号八进制整数。%s— 打印字符串%u— 打印无符号整数。%x, %X— 打印十六进制的无符号整数。%X使用A~F表示字母;%x使用a~f表示字母。%%— 打印%。
除了可以格式化输出, AWK 还可以像 grep 那样做过滤。
$ awk '/ac/ {print $0}' employee.txt (1)
ajay manager account 45000
sunil clerk account 25000
amit manager account 47000| 1 | /ac/ 表示过滤出包含 ac 字符串的行,类似 grep ac |
还可以反向过滤:
$ awk '! /ac/ {print $0}' employee.txt
varun manager sales 50000
tarun peon sales 15000
deepak clerk sales 23000
sunil peon sales 13000
satvik director purchase 80000结合上面的变量,还可以输出奇数行:
$ awk ' NR % 2 == 1 {print $1, $NF}' employee.txt
ajay 45000
varun 50000
tarun 15000
sunil 13000还可以输出第三行以后的内容:
$ awk ' NR > 3 {print $1, $NF}' employee.txt
amit 47000
tarun 15000
deepak 23000
sunil 13000
satvik 80000还可以让指定列等于指定值:
$ awk '$2 == "manager" {print $1, $NF}' employee.txt
ajay 45000
varun 50000
amit 47000过滤条件还支持逻辑运算符。假如我们第一列是标题,那么第一列肯定是要输出的。可以这样写:
$ awk '$2 == "clerk" || NR == 1 {print $1, $2}' employee.txt
ajay manager (1)
sunil clerk
deepak clerk| 1 | 由于示例数据没有标题,这就是第一行数据。 |
来试试试试与运算符:
$ awk '$2 == "clerk" && $3 == "sales" {print $1, $2, $3}' employee.txt
deepak clerk sales初次之外, AWK 还支持 if ~ else 语句:
$ awk '{ if(NR % 2 == 1) print $1, $NF; else print "///" }' employee.txt
ajay 45000
///
varun 50000
///
tarun 15000
///
sunil 13000
///当然,省掉 else 部分也是可以的:
$ awk '{ if(NR % 2 == 1) print $1, $NF }' employee.txt
ajay 45000
varun 50000
tarun 15000
sunil 13000开篇就做了说明, AWK 其实是一门编程语言。那么,内置函数必定是支持的。
首先,看一个字符串处理的函数:
$ awk '{print toupper($1)}' employee.txt
AJAY
SUNIL
VARUN
AMIT
TARUN
DEEPAK
SUNIL
SATVIK再来看看 substr 结合 touuper 完成首字母大写操作:
$ awk '{print toupper(substr($1, 1, 1)) substr($1, 2)}' employee.txt
Ajay
Sunil
Varun
Amit
Tarun
Deepak
Sunil
SatvikAWK 的内置函数还有很多,详细信息请看 Functions (The GNU Awk User’s Guide)。
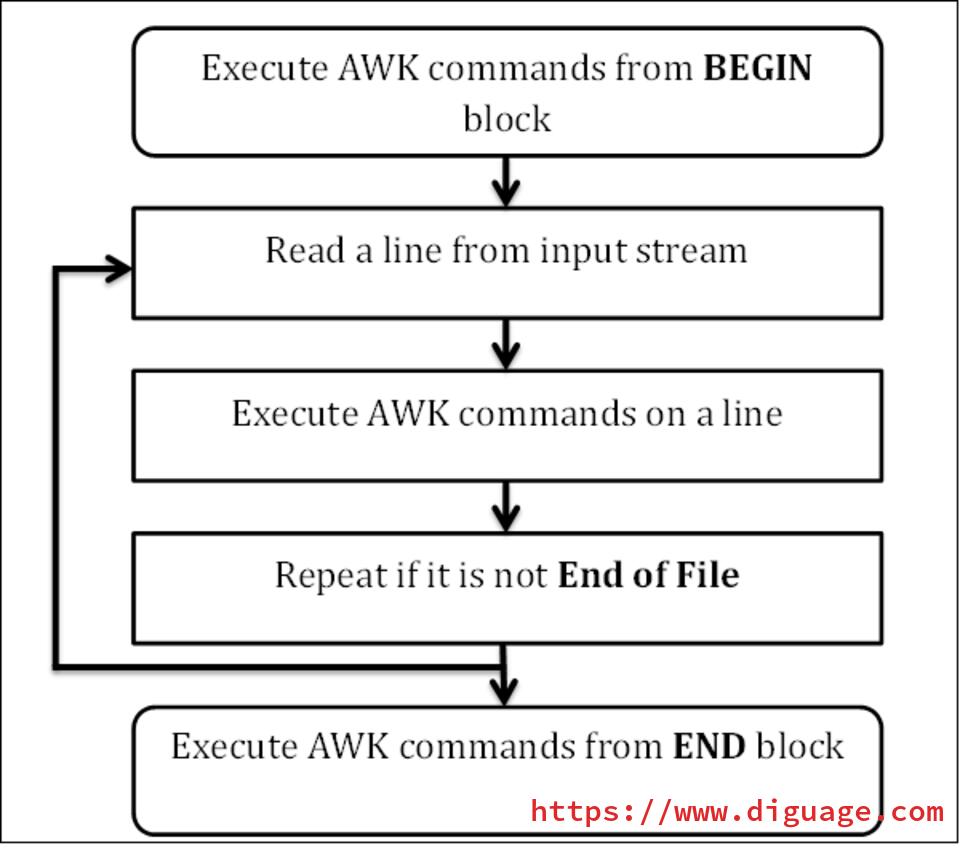
下面给大家介绍一下 AWK 工作流程: AWK 还可以通过 BEGIN 和 END 来指定前置处理和后置处理。整个工作流程如下:
下面来演示一下:
$ awk 'BEGIN{printf "\n%-7s %-9s %-8s %6s\n","Name","Title","Tag","Salary"} \ (1)
{printf "%-7s %-9s %-8s %6d\n", $1, $2, $3, $4} \ (2)
{sum += $4} \ (3)
END{printf "\nSum ---------------------- %d\n", sum; \ (4)
printf "Avg ---------------------- %6d\n", sum/NR;}' employee.txt
Name Title Tag Salary
ajay manager account 45000
sunil clerk account 25000
varun manager sales 50000
amit manager account 47000
tarun peon sales 15000
deepak clerk sales 23000
sunil peon sales 13000
satvik director purchase 80000
Sum ---------------------- 298000
Avg ---------------------- 37250| 1 | 使用 BEGIN 输出标题 |
| 2 | 格式化输出 |
| 3 | 求收入总和 |
| 4 | 使用 END 输出总和和平均值 |
require 'sinatra' (1)
get '/hi' do (2)
"Hello World!" (3)
end| 1 | Library import |
| 2 | URL mapping |
| 3 | Content for response |
今天暂且学习到此。随着对 AWK 的学习越来越深入,感觉其越来越博大精深。值得研究的点还有很多,后续再写文章介绍。