Google 三驾马车:MapReduce、GFS、Bigtable
MapReduce
MapReduce编程模型来自函数式编程,包含两个最基本的算子:map,reduce
将一个运算任务分解成大量独立正交的子任务,每个子任务通过map算子计算,得到中间结果,然后用reduce算子进行聚合,得到最终结果。
这两个算子有一个很重要的特征:确定性的纯过程调用(pure function),函数既不会修改输入,也不存在中间状态,也没有共享的内存。因此,输入一致的情况下,输出也是一致的,这大大方便了容错性设计。

系统中有两类主要的进程节点:master(单点),worker(多个)。其中,worker根据不同的计算任务,又分为map worker(对应上图中的Map phase)、reduce worker(对应上图中的Reduce phase)。
master是系统的中心节点,负责计算任务到worker节点的分配,同时监控worker节点的状态。如果某个worker计算太慢,或者宕机,master会将该worker进程负责的计算任务转移到其他进程。
map worker从GFS(google file system)中读取输入数据,然后将中间结果写到本地文件;reduce worker从master处得知中间结果的问题,通过rpc读取中间文件,计算之后将最终结果写入到可靠存储GFS。生产环境中,一个MapReduce过程的输出通常是另一个MapReduce计算的输入,类似Unix 的 pipeline,只不过unix pipeline通过stdin、stdout连接两个程序,而MapReduce使用GFS连接两个计算过程。
Scalability
由于计算任务的正交性,很容易通过增加map worker、reduce worker来处理计算任务的增长。Input file 到 Map phase这个阶段,使用了基于范围(range based)的分片方法,master作为元数据服务器会记录split到worker的映射关系。
Availability
系统对worker的容错性较好,但对master的容错性较差。
对于map worker,计算结果是写到本地文件,本地文件的位置需要通知到master,即使同一个task被多个map worker执行,单点的master只会采纳一份中间结果。而且上面提到了map function是pure function,所以计算结果也是一样的。
对于reduce worker,reduce task的计算结果会先写到临时文件(temporary file),task完成之后再重命名写入gfs,那么如果一个reduce task再多个reduce worker上计算,那么会不会有问题呢,答案是不会的
Performance
data locality — 将任务调度到数据所在的节点进行计算,减少网络传输;
backup task — master在发现某个worker上的task进展异常缓慢的时候,会将这个task调度到其他worker,以缩短这个任务(Job)的完成时间。
GFS
GFS(Google File System)是Google研发的可伸缩、高可用、高可靠的分布式文件系统,提供了类似POSIX的API,按层级目录来组织文件。
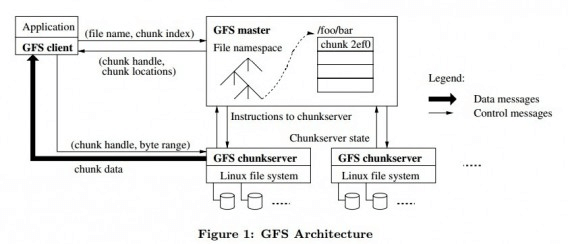
GFS master、GFS Client、GFS chunkserver。其中,GFS master任意时刻只有一个,而chunkserver和gfs client可能有多个。
一份文件被分为多个固定大小的chunk(默认64M),每个chunk有全局唯一的文件句柄 -- 一个64位的chunk ID,每一份chunk会被复制到多个chunkserver(默认值是3),以此保证可用性与可靠性。chunkserver将chunk当做普通的Linux文件存储在本地磁盘上。
GFS master是系统的元数据服务器,维护的元数据包括:命令空间(GFS按层级目录管理文件)、文件到chunk的映射,chunk的位置。其中,前两者是会持久化的,而chunk的位置信息来自于Chunkserver的汇报。
GFS master还负责分布式系统的集中调度:chunk lease管理,垃圾回收,chunk迁移等重要的系统控制。master与chunkserver保持常规的心跳,以确定chunkserver的状态。
GFS client是给应用使用的API,这些API接口与POSIX API类似。GFS Client会缓存从GFS master读取的chunk信息(即元数据),尽量减少与GFS master的交互。
一个文件读操作的流程是这样的:
应用程序调用GFS client提供的接口,表明要读取的文件名、偏移、长度。
GFS Client将偏移按照规则翻译成chunk序号,发送给master — chunk序号是怎么生成的?
master将chunk id与chunk的副本位置告诉GFS client
GFS client向最近的持有副本的Chunkserver发出读请求,请求中包含chunk id与范围
ChunkServer读取相应的文件,然后将文件内容发给GFS client。
副本控制协议
GFS采用的是中心化副本控制协议,即对于副本集的更新操作有一个中心节点来协调管理,将分布式的并发操作转化为单点的并发操作,从而保证副本集内各节点的一致性。在GFS中,中心节点称之为Primary,非中心节点成为Secondary。中心节点是GFS Master通过lease选举的。
GFS中,数据的冗余是以Chunk为基本单位的,而不是文件或者机器。
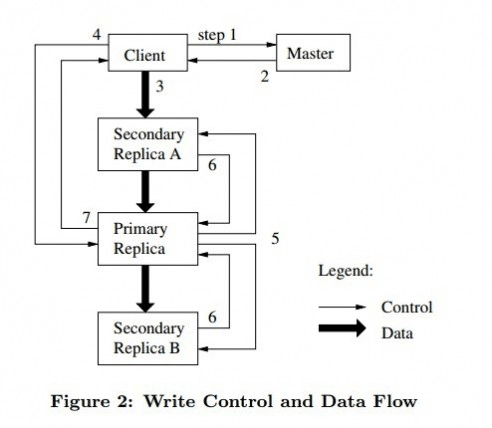
step1 Client向master请求Chunk的副本信息,以及哪个副本(Replica)是Primary
step2 maste回复client,client缓存这些信息在本地
step3 client将数据(Data)链式推送到所有副本
step4 Client通知Primary提交
step5 primary在自己成功提交后,通知所有Secondary提交
step6 Secondary向Primary回复提交结果
step7 primary回复client提交结果
为什么将数据流与控制消息分开,且采用链式推送方法呢,目标是最大化利用每个机器的网络带宽,避免网络瓶颈和高延迟连接,最小化推送延迟。
上述流程中第3三步,只是将数据写到了临时缓存,真正生效还需要控制消息(第4 5步)。在GFS中,控制消息的写入是同步的,即Primary需要等到所有的Secondary的回复才返回客户端。这就是write all, 保证了副本间数据的一致性,因此可以读取的时候就可以从任意副本读数据。
高性能、高可用的 Master
如何避免单点成为瓶颈?两个可行的办法:减少交互,快速的failover。
GFS client尽量较少与GFS master的交互:缓存与批量读取(预读取)。
master的高可用是通过操作日志的冗余 + 快速failover来实现的。
master 重新启动之后(不管是原来的物理机重启,还是新的物理机),都需要恢复内存状态,一部分来之checkpoint与操作日志,另一部分(即chunk的副本位置信息)则来自chunkserver的汇报。
Scalability
直接往系统中添加Chunkserver即可。
Availability
数据以chunk为单位冗余在多个chunkserver上,而且,默认是跨机架(rack)的冗余。
当Master发现了某个chunk的冗余副本数目达不到要求时(比如某个chunkserver宕掉),会为这个chunk补充新的副本;当有新的chunkserver添加到系统中时,也会进行副本迁移--将chunk为负载较高的chunkserver迁移到负载低的chunkserver上,达到动态负载均衡的效果。
当需要选择一个chunkserver来持久化某个chunk时,会考虑以下因素:
选择磁盘利用率降低的chunkserver;
不希望一个chunkserver在短时间创建大量chunk;
chunk要跨机架
可靠性
可靠性指数据不丢失、不损坏(data corruption)。副本冗余机制保证了数据不会丢失;而GFS还提供了checksum机制,保证数据不会因为磁盘原因损坏。
Bigtable
A Bigtable is a sparse, distributed, persistent multidimensional sorted map.
Bigtable是结构化(Structured)数据,colume family在定义表(table)的时候就需要创建,colume family一般数量较少,但colume family下面的colume是动态添加的,数量可以很多。
存储
tablet是Bigtable中数据分片和负载均衡的基本单位(the unit of distribution and load balancing.),大小约为100M到200M,其概念等价于GFS、MongoDB中的chunk。简单来说,就是由连续的若干个row组成的一个区块,BIgtable维护的是tablet到tablet server的映射关系,当需要迁移数据的时候,也是与tablet为单位。
tablet采用的是range-based的分片方式,相近的row会被划分在同一个tablet里面,range based对于范围查询是非常友好的。
tablet内部采用了类似LSM(log-Structured merge)Tree的存储方式,有一个memtable与多个sstable(sorted string table)组成。
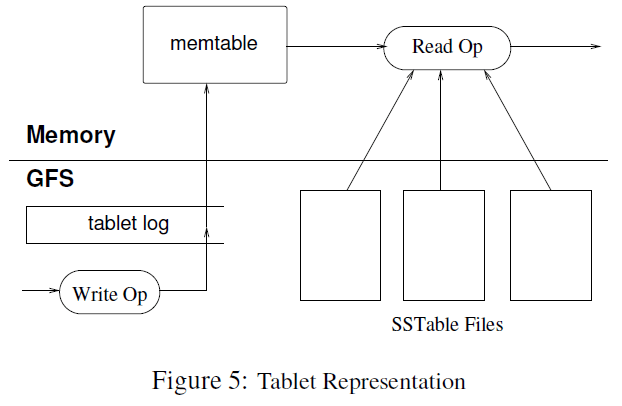
sstable是bigtable数据物理存储的基本单位。在sstable内部,一个sstable包含多个block(64kb为单位),block index放在sstable末尾,open sstable的时候block index会被加载到内存,二分查找block index就能找到需要的block,加速磁盘读取。在特殊情况下,sstable也是可以强制放在内存的。
写操作较为简单,写到memtable就可以了。而对于读操作,则需要merge memtable与SSTable中的数据。
SSTable 的内容可以在 Designing Data-Intensive Applications 之 Storage and Retrieval 中有更详细介绍。
系统架构
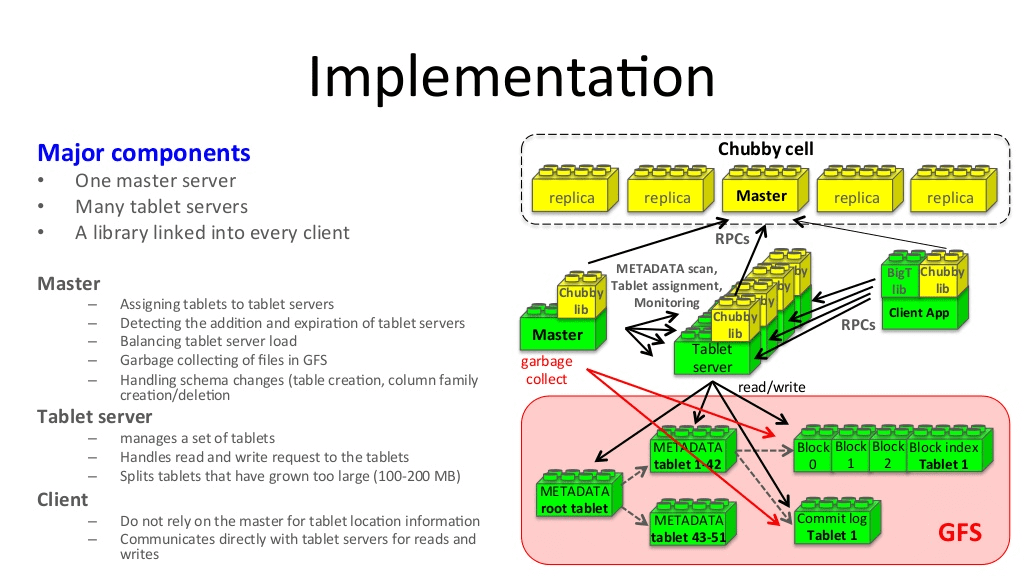
分布式文件系统常用的架构范式就是“元数据总控+分布式协调调度+分区存储”。
在Bigtable中,Chubby负责了元数据总控,master负责分布式协调调度。
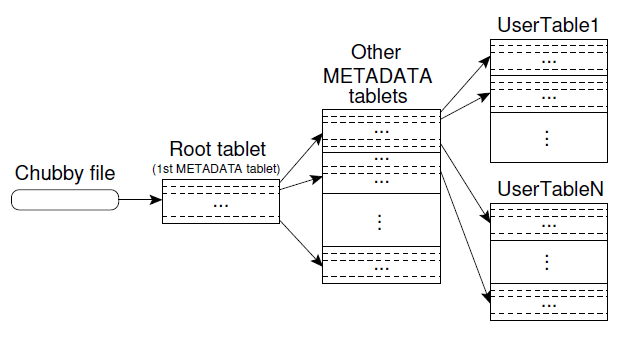
系统采用了类似B+树的三层结构来维护tablet location信息
Chubby中存储的只是root tablet的位置信息,数据量很少。在Root tablet里面,维护的是METADATA tablets的位置信息;METADATA tablet存储的则是应用的tablet的位置信息。
系统也做了一些工作,来减轻存储METADATA tablets 的 tablet server的负担,首先METADATA tablet对应的sstable存储在内存中,无需磁盘操作。其次,bigtable client会缓存元数据信息,而且会prefetch元数据信息,减少交互。
单点 Master
Bigtable中,master是无状态的单点,无状态是指master本身没有需要持久化的数据。
首先,master的负载并不高,Bigtable client并不与master直接交互。
其次,即使master fail(由于crash或者network partition),系统会创建新的master,并在内存中恢复元数据(tablets到tablet server的映射、尚未分配的tablets)。
Simple is Better Than Complex.