Redis 核心数据结构(二)
在上一篇文章: Redis 核心数据结构(1) 中,介绍了链表、ziplist、quicklist 数据结构。这篇文章,来介绍一下 skiplist、dict。
skiplist
跳跃表是一种有序数据结构,支持平均 O(logN)、最坏 O(N) 复杂度的节点查找;大部分情况效率可以和平衡树相媲美,实现却比平衡树简单。
跳跃表就是 Redis 中有序集合键的底层实现之一。
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;skiplist,顾名思义,首先它是一个list。实际上,它是在有序链表的基础上发展起来的。

当我们想查找数据的时候,可以先沿着跨度大的链进行查找。当碰到比待查数据大的节点时,再回到跨度小的链表中进行查找。
skiplist正是受这种多层链表的想法的启发而设计出来的。按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到 O(logN)。但是,存在的一个问题是:如果插入新节点后就会打乱上下相邻两层节点是 2:1 的对应关系。如果要维持,则需要调整后面所有的节点。
skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。
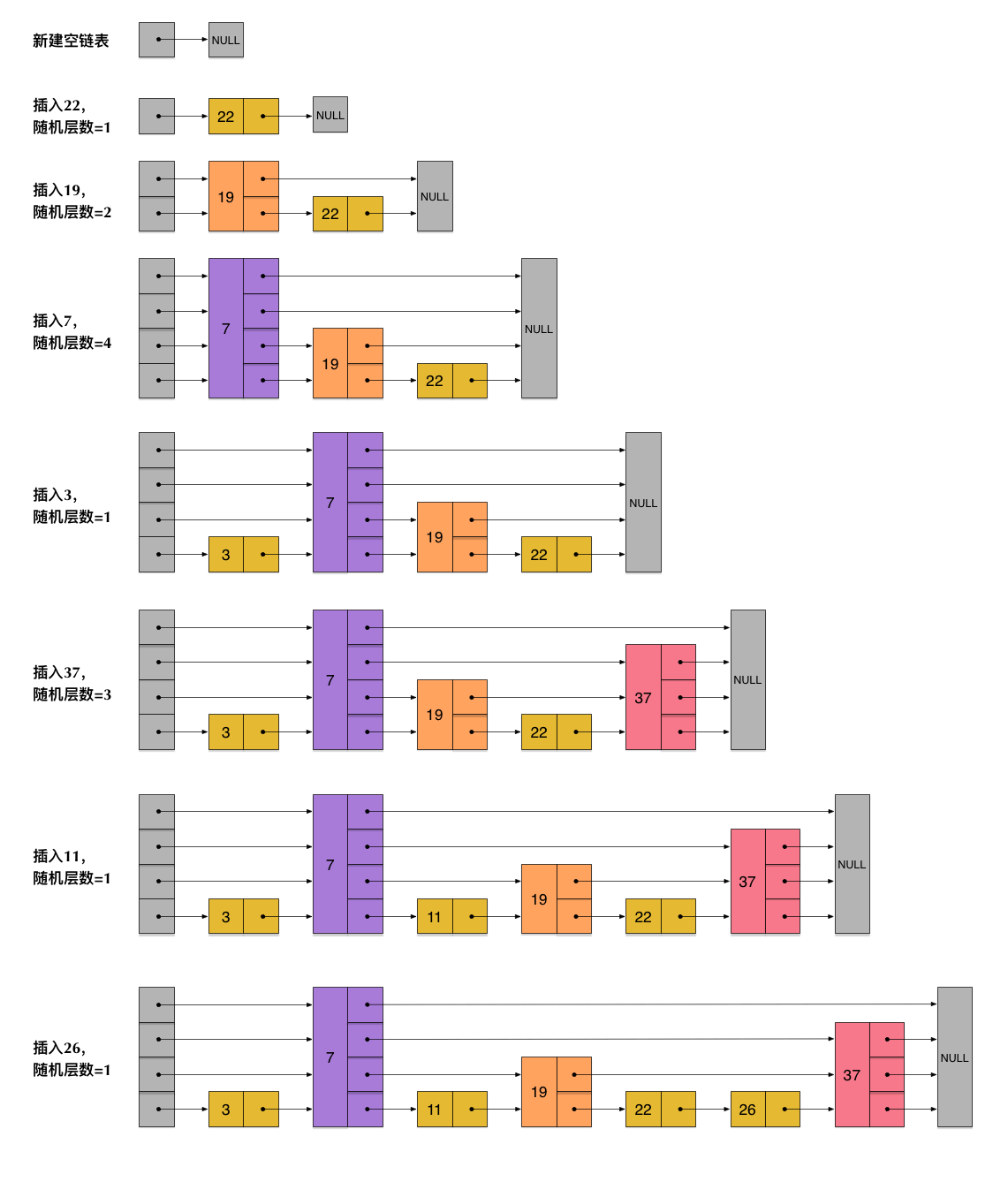
插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是 skiplist 的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。
skiplist,翻译成中文,可以翻译成“跳表”或“跳跃表”,指的就是除了最下面第1层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针故意跳过了一些节点(而且越高层的链表跳过的节点越多)。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。在这个过程中,我们跳过了一些节点,从而也就加快了查找速度。
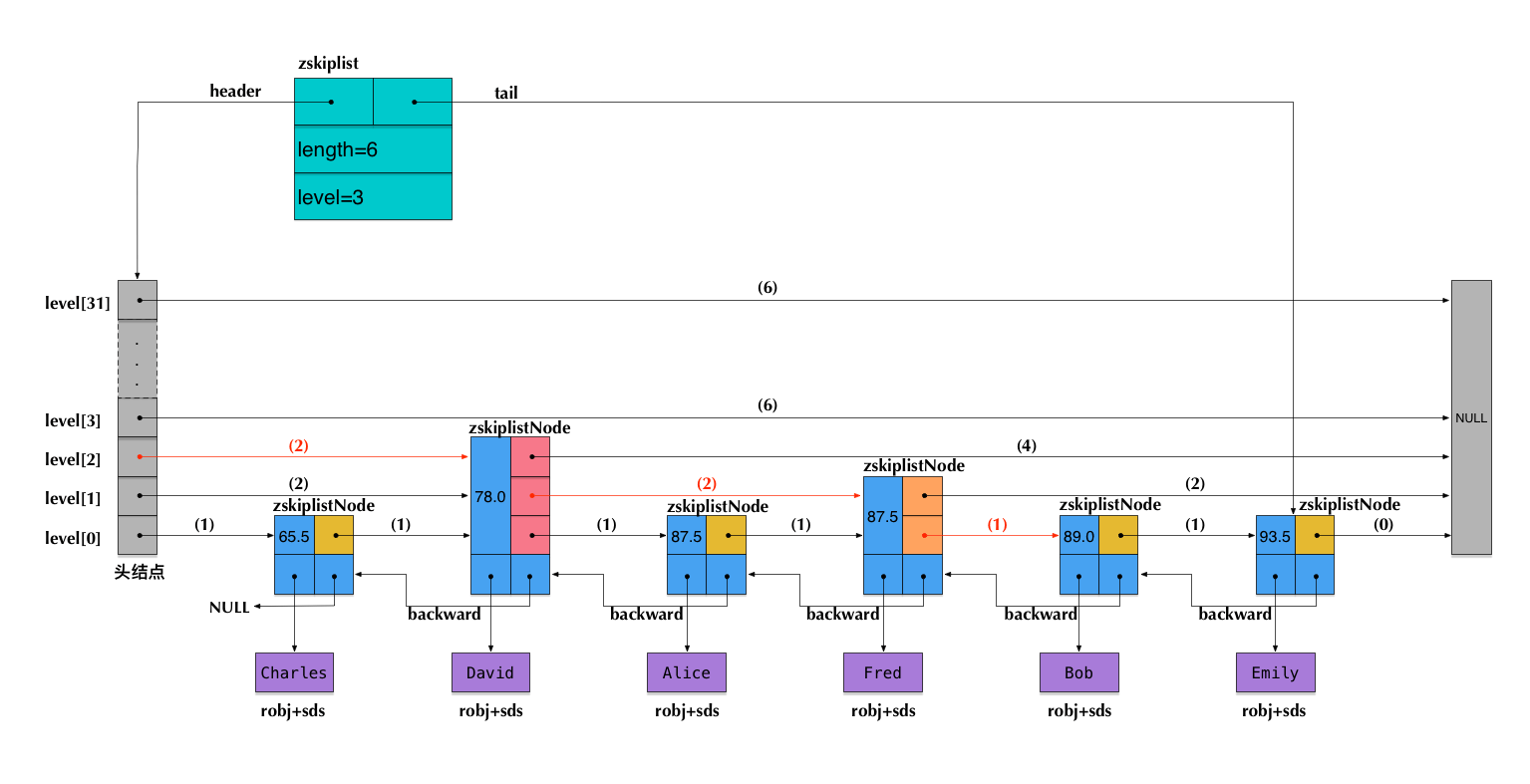
skiplist 中 key 允许重复。
在比较时,不仅比较分数(即key),还要比较数据自身。
第一层链表是双向链表,并且反向指针只有一个。
在 skiplist 中可以很方便计算每个元素的排名。
Redis 中的有序集合(sorted set),是在 skiplist, dict 和 ziplist 基础上构建起来的:
当数据较少时,sorted set是由一个 ziplist 来实现的。其中集合元素按照分值从小到大排序。
当数据多的时候,sorted set 是由一个叫 zset 的数据结构来实现的,这个 zset 包含一个 dict + 一个 skiplist。dict 用来查询数据到分数(score)的对应关系,而 skiplist 用来根据分数查询数据(可能是范围查找)。
转换的条件是:
有序集合保存的元素数量小于 128 个;(通过参数
zset-max-ziplist-entries来调节,默认为 128。)有序集合保存的所有元素成员的长度都要小于 64 个字节;(通过参数
zset-max-ziplist-value来调节,默认为 64。)
在 t_zset.c/zsetConvert 中执行转换操作。
$ redis-cli --raw
127.0.0.1:6379> ZADD NameRanking 1 "D瓜哥"
1
127.0.0.1:6379> ZADD NameRanking 2 "https://www.diguage.com"
1
127.0.0.1:6379> ZADD NameRanking 3 "https://github.com/diguage"
1
127.0.0.1:6379> ZRANGE NameRanking 0 -1 WITHSCORES
D瓜哥
1
https://www.diguage.com
2
https://github.com/diguage
3
127.0.0.1:6379> TYPE NameRanking
zset
127.0.0.1:6379> OBJECT encoding NameRanking
ziplist
127.0.0.1:6379> ZADD NameRanking 4 "1234567890123456789012345678901234567890123456789012345678901234"
1
127.0.0.1:6379> ZRANGE NameRanking 0 -1 WITHSCORES
D瓜哥
1
https://www.diguage.com
2
https://github.com/diguage
3
1234567890123456789012345678901234567890123456789012345678901234
4
127.0.0.1:6379> OBJECT encoding NameRanking
ziplist
127.0.0.1:6379> ZADD NameRanking 5 "12345678901234567890123456789012345678901234567890123456789012345"
1
127.0.0.1:6379> ZRANGE NameRanking 0 -1 WITHSCORES
D瓜哥
1
https://www.diguage.com
2
https://github.com/diguage
3
1234567890123456789012345678901234567890123456789012345678901234
4
12345678901234567890123456789012345678901234567890123456789012345
5
127.0.0.1:6379> OBJECT encoding NameRanking
skiplist
127.0.0.1:6379> TYPE NameRanking
zset在 JDK 中,也有 skiplist 的实现,在 ConcurrentSkipListMap 中。不过,它不是作为一个独立的 Collection 来实现的,而是作为 Map 的一部分来实现的。
dict
Redis 底层中的字典就是一个典型的 Hash 实现。
typedef struct dictEntry { (1)
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table; (2)
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; (3)
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;| 1 | dictEntry 保存一个键值对。 |
| 2 | table 属性是一个数组,数组中每个元素都是一个指向 dictEntry 结构的指针。 |
| 3 | 通常使用 ht[0],ht[1] 在 Rehash 时才会用到。 |
添加新元素时,和 Java 一样,计算 Key 的哈希值,然后再根据哈希值与长度掩码(sizemask)相与得到数组下标。
Redis 底层使用 MurmurHash2 算法来计算键的哈希值。
Rehash 操作
计算新的数组长度
如果是扩容,则
used * 2;如果是缩容,则是第一个大于等于
used的 2n。 — 这点和 Java 不同,HashMap中没有自动缩容的机制。
将
ht[0]中的所有键值对重新 Rehash,重新计算哈希值和索引值,放置到ht[1]上;迁移完成后,将
ht[1]设置为ht[0],为ht[1]创建一个空白哈希表。
还有几点需要特别注意:
根据是否正在执行
BGSAVE或BGREADWRITEAOF命令,使用不同的负载阈值来决定是否开启对哈希表的自动扩展工作;当哈希表负载因子小于 0.1 时,会自动开始对哈希表缩容;
Rehash 过程是渐进式的:
开始 Rehash 后,每次对自动进行的添加、删除、查找或更新时,程序会自动将对应的键值对从
ht[0]Rehash 到ht[1]上;rehashidx 属性值增一。记得有后台定时任务来自动扩展的,怎么没有看到说明文档?
Redis 在哈希对象上的编码有可能是:
ziplist
hashtable
转换条件是:
哈希对象保存的所有键值对象字符串长度都小于 64 个字节;(通过参数
hash-max-ziplist-value来调节,默认为 64)哈希对象保存的键值对数量小于 512 个;(通过参数
hash-max-ziplist-entries来调节,默认为 512)
$ redis-cli --raw
127.0.0.1:6379> HMSET profile name "D瓜哥" site "https://www.diguage.com" job "Developer"
OK
127.0.0.1:6379> TYPE profile
hash
127.0.0.1:6379> OBJECT encoding profile
ziplist
127.0.0.1:6379> HSET profile address "1234567890123456789012345678901234567890123456789012345678901234" (1)
1
127.0.0.1:6379> HVALS profile
D瓜哥
https://www.diguage.com
Developer
1234567890123456789012345678901234567890123456789012345678901234
127.0.0.1:6379> OBJECT encoding profile
ziplist
127.0.0.1:6379> HSET profile address "12345678901234567890123456789012345678901234567890123456789012345" (2)
0
127.0.0.1:6379> HVALS profile
https://www.diguage.com
D瓜哥
12345678901234567890123456789012345678901234567890123456789012345
Developer
127.0.0.1:6379> OBJECT encoding profile
hashtable| 1 | 这是 64 个字符。 |
| 2 | 这是 65 个字符。 |
通过 t_hash.c/hashTypeConvertZiplist 方法来转换。
总结
下面从 Redis 接口的层面,来看一下底层实现时用到的数据结构:
Redis 中并没有直接使用以上所说的各种数据结构来实现键值数据库,而是基于一种对象,对象底层再间接的引用上文所说的具体的数据结构。结构如下图:
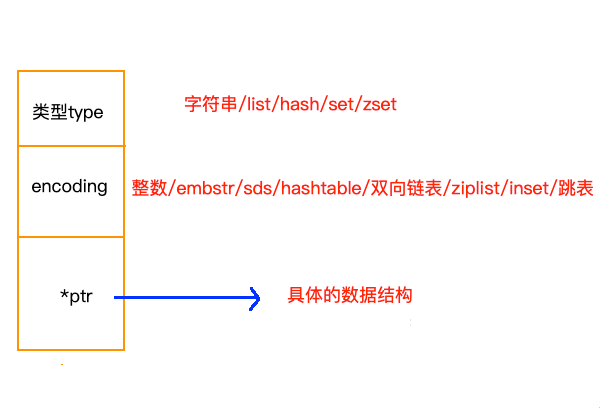
注:图中 inset 是笔误,应该是 intset。
字符串(strings)
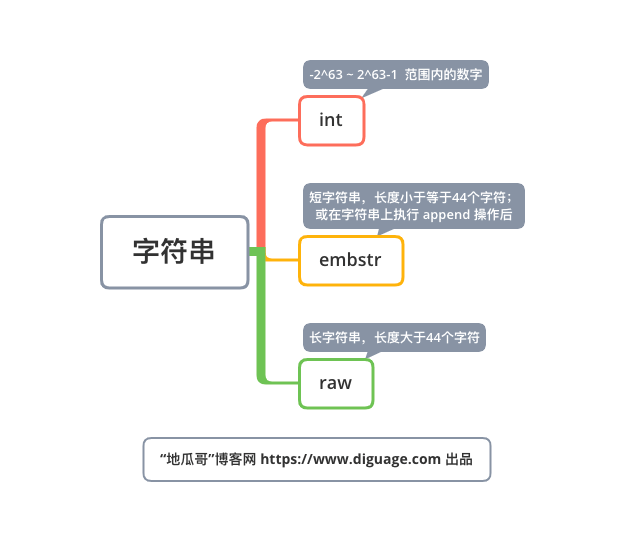
int 编码的数字范围是: -263 ~ 263 - 1,超出这个范围就会变成 embstr。
127.0.0.1:6379> set n63 9223372036854775807
OK
// 2^63^ - 1 为 int
127.0.0.1:6379> OBJECT encoding n63
int
127.0.0.1:6379> set n64 9223372036854775808
OK
// 2^63^ - 1 不能再自增,否则报溢出错误
127.0.0.1:6379> INCR n63
ERR increment or decrement would overflow
// 2^63^ 为 embstr
127.0.0.1:6379> OBJECT encoding n64
embstr
// -2^63^ 为 int
127.0.0.1:6379> set n-63 -9223372036854775808
OK
127.0.0.1:6379> OBJECT encoding n-63
int
// -2^63^ 不能自减,否则报溢出错误
127.0.0.1:6379> DECR n-63
ERR increment or decrement would overflowembstr 和 raw 都是由SDS动态字符串构成的。唯一区别是:raw 是分配内存的时候,redisobject 和 sds 各分配一块内存,而 embstr 是 redisobject 和 raw 在一块儿内存中。两者的界限在 object.c/OBJ_ENCODING_EMBSTR_SIZE_LIMIT 常量中定义,不能通过参数调节。
$ redis-cli --raw
127.0.0.1:6379> APPEND names 119
3
127.0.0.1:6379> GET names
119
127.0.0.1:6379> TYPE names
string
127.0.0.1:6379> OBJECT encoding names
int
127.0.0.1:6379> APPEND names " D瓜哥"
11
127.0.0.1:6379> GET names
119 D瓜哥
// 注意:这里出现了 raw
127.0.0.1:6379> OBJECT encoding names
raw
127.0.0.1:6379> SET names "119 D瓜哥"
OK
127.0.0.1:6379> GET names
119 D瓜哥
// 注意:直接 SET 确实 embstr 编码
127.0.0.1:6379> OBJECT encoding names
embstr
127.0.0.1:6379> SET names "D瓜哥 https://www.diguage.com/"
OK
127.0.0.1:6379> GET names
D瓜哥 https://www.diguage.com/
127.0.0.1:6379> OBJECT encoding names
embstr
127.0.0.1:6379> SET names "01234567890123456789012345678901234567890123"
OK
127.0.0.1:6379> GET names
01234567890123456789012345678901234567890123
// 注意:44 个是 embstr
127.0.0.1:6379> OBJECT encoding names
embstr
127.0.0.1:6379> SET names "012345678901234567890123456789012345678901234"
OK
127.0.0.1:6379> GET names
012345678901234567890123456789012345678901234
// 注意:45 个是 raw
127.0.0.1:6379> OBJECT encoding names
raw散列(hashes)
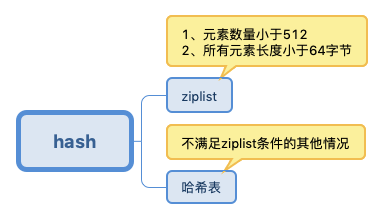
Redis 的散列(hashes)的底层存储可以使用 ziplist 和 hashtable。当散列(hashes)可以同时满足以下两个条件时,散列(hashes)使用 ziplist 编码。
散列(hashes)保存的所有键值对的键和值的字符串长度都小于 64 字节。(通过参数
hash-max-ziplist-value来调节,默认是 64)散列(hashes)保存的键值对数量小于 512 个。(通过参数
hash-max-ziplist-entries来调节,默认是 512)
使用 ziplist 编码,每个 key/value 存储结果中 key 用一个 zipEntry 存储,value 用一个 zipEntry 存储。
$ redis-cli --raw
127.0.0.1:6379> HMSET profile name "D瓜哥" site "https://www.diguage.com" job "Developer"
OK
127.0.0.1:6379> TYPE profile
hash
127.0.0.1:6379> OBJECT encoding profile
ziplist
127.0.0.1:6379> HSET profile address "1234567890123456789012345678901234567890123456789012345678901234" (1)
1
127.0.0.1:6379> HVALS profile
D瓜哥
https://www.diguage.com
Developer
1234567890123456789012345678901234567890123456789012345678901234
127.0.0.1:6379> OBJECT encoding profile
ziplist
127.0.0.1:6379> HSET profile address "12345678901234567890123456789012345678901234567890123456789012345" (2)
0
127.0.0.1:6379> HVALS profile
https://www.diguage.com
D瓜哥
12345678901234567890123456789012345678901234567890123456789012345
Developer
127.0.0.1:6379> OBJECT encoding profile
hashtable| 1 | 这是 64 个字符。 |
| 2 | 这是 65 个字符。 |
列表(lists)
列表(lists)底层是用 quicklist。
查看 Redis 的 t_list.c 文件的提交记录可以看出,从 2014 年 Redis 实现了 quicklist 之后,就把 列表(lists)的实现全部改成 quicklist 来实现了。网上很多很多资料显示列表(lists)有两种不同的编码方案,那都已经过时了。
$ redis-cli --raw
127.0.0.1:6379> RPUSH names diguage "D瓜哥" "https://www.diguage.com/"
2
127.0.0.1:6379> LRANGE names 0 -1
diguage
D瓜哥
https://www.diguage.com/
127.0.0.1:6379> TYPE names
list
127.0.0.1:6379> OBJECT encoding names
quicklist集合(sets)
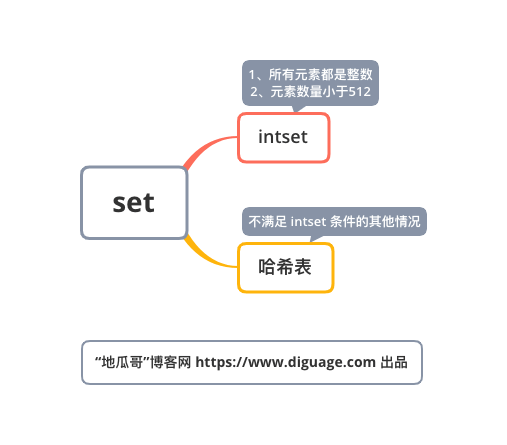
Redis 的集合(sets)的底层存储可以使用 intset 和 hashtable。当集合(sets)可以同时满足以下两个条件时,集合(sets)使用 intset 编码。
集合(sets)保存的所有值都是整数,而且数字范围在 -264 ~ 264-1 之间。
集合(sets)保存的键数量小于 512 个,(通过
set-max-intset-entries参数调节,默认是 512)。
$ redis-cli --raw
127.0.0.1:6379> SADD numbers 1 2 3
3
127.0.0.1:6379> SMEMBERS numbers
1
2
3
127.0.0.1:6379> TYPE numbers
set
127.0.0.1:6379> OBJECT encoding numbers
intset
127.0.0.1:6379> SADD numbers "https://www.diguage.com"
1
127.0.0.1:6379> SMEMBERS numbers
https://www.diguage.com
2
1
3
127.0.0.1:6379> TYPE numbers
set
127.0.0.1:6379> OBJECT encoding numbers
hashtable有序集合(sorted sets)
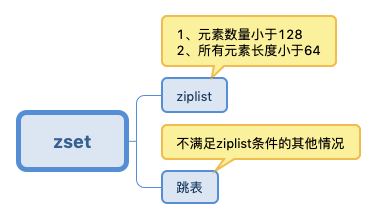
当数据较少时,sorted set是由一个 ziplist 来实现的。其中集合元素按照分值从小到大排序。
当数据多的时候,sorted set 是由一个叫 zset 的数据结构来实现的,这个 zset 包含一个 dict + 一个 skiplist。dict 用来查询数据到分数(score)的对应关系,而 skiplist 用来根据分数查询数据(可能是范围查找)。查看编码显示的是 skiplist。
转换的条件是:
有序集合保存的元素数量小于 128 个;(通过参数
zset-max-ziplist-entries来调节,默认为 128。)有序集合保存的所有元素成员的长度都要小于 64 个字节;(通过参数
zset-max-ziplist-value来调节,默认为 64。)
$ redis-cli --raw
127.0.0.1:6379> ZADD NameRanking 1 "D瓜哥"
1
127.0.0.1:6379> ZADD NameRanking 2 "https://www.diguage.com"
1
127.0.0.1:6379> ZADD NameRanking 3 "https://github.com/diguage"
1
127.0.0.1:6379> ZRANGE NameRanking 0 -1 WITHSCORES
D瓜哥
1
https://www.diguage.com
2
https://github.com/diguage
3
127.0.0.1:6379> TYPE NameRanking
zset
127.0.0.1:6379> OBJECT encoding NameRanking
ziplist
127.0.0.1:6379> ZADD NameRanking 4 "1234567890123456789012345678901234567890123456789012345678901234"
1
127.0.0.1:6379> ZRANGE NameRanking 0 -1 WITHSCORES
D瓜哥
1
https://www.diguage.com
2
https://github.com/diguage
3
1234567890123456789012345678901234567890123456789012345678901234
4
127.0.0.1:6379> OBJECT encoding NameRanking
ziplist
127.0.0.1:6379> ZADD NameRanking 5 "12345678901234567890123456789012345678901234567890123456789012345"
1
127.0.0.1:6379> ZRANGE NameRanking 0 -1 WITHSCORES
D瓜哥
1
https://www.diguage.com
2
https://github.com/diguage
3
1234567890123456789012345678901234567890123456789012345678901234
4
12345678901234567890123456789012345678901234567890123456789012345
5
127.0.0.1:6379> OBJECT encoding NameRanking
skiplist
127.0.0.1:6379> TYPE NameRanking
zset写这个总结,内容不多,但是却花了好长时间,原因如下:
随着 Redis 的演进,网上的文章很多很多过时,比如现在已经不用 linkedlist,而改用 quicklist 了;
网上的资料有错的(注意:D瓜哥的文章也可能会有错,如有发现欢迎留言指正)。
D瓜哥对C语言不熟,本地调试环境没有搞好,只能翻代码生看,看代码效率就比较低;
D瓜哥尽量查资料、看代码来确保这些资料的正确性了。不尽之处,还请不吝指正。另外,还有些地点值得动笔,比如网络模型;比如缓存删除算法的更新,后续有机会再写吧。