Avro、ProtoBuf、Thrift 的模式演进之法【翻译】

如果有一些数据,想存储在文件中,或者通过网络发送出去,那么,可能发现自己正经历如下几个进化阶段:
使用编程语言内置的序列化机制,如 Java Serialization、 Ruby Marshal 或 Python pickle,或者甚至发明自己的格式。
然后,意识到被锁定在一种编程语言中是很糟糕的,所以转向使用一种广泛支持的、与语言无关的格式,比如 JSON (或者 XML,前提是你喜欢像 1999 年那样狂热场景)。
再然后,觉得 JSON 过于冗长,解析速度太慢。也会恼火它竟然无法区分整数和浮点。假如非常喜欢二进制字符串和 Unicode 字符串。最终,你发明了一种类似于 JSON 的格式,但它是二进制的,例如( ①MessagePack、 ②BSON、 ③UBJSON、 ④BJSON、⑤失链啦、 ⑥Binary JSON)。
最后,会发现人们使用不一致的类型将各种随机字段填充到他们的对象中,非常希望有模式和一些文档。也许你在使用静态类型编程语言,并希望从模式生成模型类。此外,你还意识到,类似于 JSON 的二进制文件并没有那么紧凑,因为仍然会一遍又一遍地存储字段名。如果有一个模式,就可以避免存储对象的字段名,则可以节省更多字节!
一旦你进入到第四个阶段,可用选项通常是 Thrift, Protocol Buffers(以下简称 ProtoBuf)或Avro。基于模式,这三种方法都为 Java 开发人员提供了,高效的、跨语言数据序列化和代码生成。
| 以 D瓜哥 现在的经验来看,Martin Kleppmann 的视角真是太棒啦!他值得一个大大的赞 👍🏻👍🏻👍🏻! |
在现实生活中,数据总是在不断变化。当你认为已经完成了一个模式时,有人会提出一个出乎意料的用例,并希望“只是快速添加一个字段”。幸运的是,Thrift、ProtoBuf 和 Avro 都支持模式演进:可以更改模式,可以让生产者和消费者同时使用不同版本的模式,并且这一切都可以继续工作。当处理一个大型生产系统时,这是一个非常有价值的特性,因为它允许在不同的时间独立地更新系统的不同组件,而不用担心兼容性。
这就引出了今天帖子的主题。我想探究 ProtoBuf、Avro 和 Thrift 实际上是如何将数据编码为字节的,这也将有助于解释它们如何处理模式变化。 每个框架所做的设计选择都很有趣,通过比较它们,我认为你可以成为一个更好的工程师(哪怕只是进步一点点)。
我将使用的示例是描述一个人的小对象。在 JSON 中,我会这样写:
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}这种 JSON 编码可以作为我们的基线。如果我删除所有空白,它将消耗 82 字节。
Protocol Buffers
person 对象的 ProtoBuf 模式可能类似于这样:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}当我们使用这个模式对上面的数据进行 编码 时,它使用 33 字节,如下所示
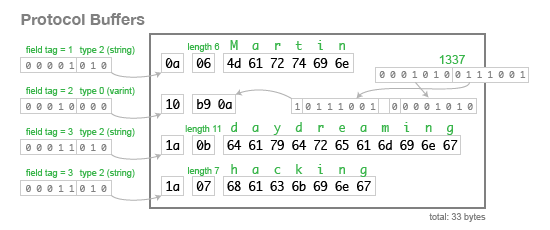
仔细看看二进制表示是如何一个字节一个字节地构造的。person 记录只是其字段的集合。每个字段都以一个字节开始,该字节指示其 Tag Number(标签号,即上面的模式中的数字1、2、3)和字段的 Type(类型)。如果字段的第一个字节表明该字段是字符串,则随后是字符串中的字节数,然后是字符串的 UTF-8 编码。如果第一个字节表示该字段是一个整数,则接下来是该数字的变长编码。没有数组类型,但是 Tag Number 可以出现多次以表示一个多值字段。
这种编码对模式演进的影响:
optional 可选,required 必需和 repeated 重复字段之间的编码没有差异(除了 Tag Number 标签号出现的次数)。这意味着您可以将字段从可选更改为重复,反之亦然(如果解析器期望一个可选字段,但在一条记录中多次看到相同的标签号,则它将丢弃除最后一个值之外的所有值)。required 必需字段有一个额外的验证检查,因此,如果您更改它,则可能会出现运行时错误(如果消息的发件人认为它是可选的,但是收件人认为这是必需的)。
没有值的可选字段或长度为零的重复字段,根本不会出现在编码数据中 - 该 Tag Number 标签号的字段根本不存在。因此,可以安全地从模式中删除这种字段。但是,以后决不能将 Tag Number 标签号用于另一个字段,因为在存储的数据,可能仍然使用该编号标记的已删除字段。
只要给出一个新的 Tag Number 标签号,就可以在记录中添加一个字段。如果 ProtoBuf 解析器看到一个没有在其模式中定义的标签号,它就无法知道该字段被称为什么。但它确实大致知道它是什么类型,因为该字段的第一个字节中包含3位类型代码。这意味着,即使解析器无法准确地解释字段,它也可以计算出需要跳过多少字节,以便在记录中找到下一个字段。
可以重命名字段,因为二进制序列化中不存在字段名称,但永远无法更改标签号。
这种使用标签号来表示每个字段的方法简单而有效。但是我们马上就会看到,这并不是做事情的唯一方法。
Avro
Avro模式可以用两种方式编写,一种是JSON格式:
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}或者使用领域专属语言:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}注意,模式中没有标签号!那么它是如何工作的呢?
这里是以 32 字节 编码 的相同示例数据:
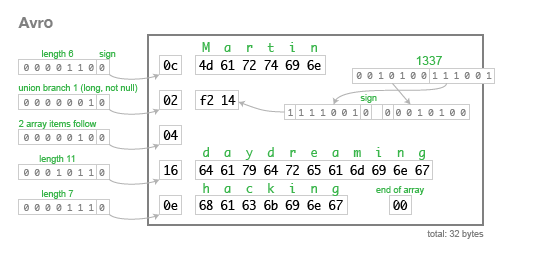
字符串只是一个长度前缀,后跟 UTF-8 字节,但字节流中没有任何信息表明它是字符串。它也可能是一个可变的整数,或者完全是其他东西。解析此二进制数据的唯一方法是将其与模式一起读取,模式将告诉您下一步将使用什么类型。需要拥有与所用数据的编写者完全相同的模式版本。如果使用了错误的模式,解析器将无法读取二进制数据的头部或尾部。
那么 Avro 如何支持模式演进?虽然需要知道写入数据的确切模式(生产者模式),但它不必与消费者期望的模式(消费者模式)相同。实际上,可以给 Avro 解析器提供两个不同的模式,它使用 解析规则 将数据从生产者模式转换为消费者模式。
| 生产者模式和消费者模式的原文分别是:the writer’s schema 和 the reader’s schema。 |
这对模式演进产生一些有趣的结果:
Avro 编码没有指示下一个字段的标识符;它只是按照字段在模式中出现的顺序,对一个又一个字段进行编码。由于解析器无法知道某个字段被跳过,所以在 Avro 中不存在可选字段。取而代之的是,如果想能够忽略一个值,则可以使用联合类型,例如上面的
{null,long}。这被编码为一个字节,告诉解析器使用哪种可能的联合类型,然后是值本身。通过与null类型结合(简单地编码为零字节),可以使字段成为可选字段。联合类型很强大,但在更改它们时必须小心。如果要向联合添加类型,首先需要用新模式更新所有消费者,以便它们知道会发生什么。只有当所有的消费者都更新之后,生产者才可以开始将这种新类型放入他们生成的数据记录中。
可以按照自己的意愿对记录中的字段进行重新排序。尽管字段按照声明的顺序编码,但解析器通过名称匹配消费者、生产者模式中的字段,这就是为什么 Avro 中不需要标记号的原因。
因为字段是按名称匹配的,所以更改字段的名称很棘手。需要首先更新数据的所有消费者,以使用新的字段名,同时保留旧名称作为别名(因为名称匹配使用消费者模式中的别名)。然后,可以更新生产者的模式以使用新的字段名称。
可以向记录中添加一个字段,前提是您还为其提供了一个默认值(例如,如果字段的类型是与
null的联合,则为null)。默认值是必要的,因此当使用新模式的读取器解析用旧模式写入的记录时(因此缺少字段),它可以填充默认值。相反,可以从记录中删除一个字段,前提是它以前有一个默认值。(如果可能的话,这是为所有字段提供默认值的一个很好的理由。)这样,当使用旧模式的消费者解析用新模式写入的记录时,它可以回退到默认值。
这给我们留下了一个问题,即知道写入给定记录的确切模式。最佳解决方案取决于使用数据的上下文:
可以这样看:在 ProtoBuf 中,记录中的每个字段都被标记;而在 Avro 中,整个记录、文件或网络连接都被标记为模式版本。
乍一看,Avro 的方法似乎有更大的复杂性,因为需要付出额外的努力来分发模式。然而,我现在认为 Avro 的方法也具有一些明显的优势:
对象容器文件具有很好的自描述功能:嵌入在文件中的生产者模式包含所有字段名称和类型,甚至包括文档字符串(如果模式的作者愿意写一些的话)。这意味着您可以直接将这些文件加载到像 Pig 这样的交互式工具中,而且它不需要任何配置就可以正常工作。
因为 Avro 模式是 JSON,可以向其添加自己的元数据,例如描述一个字段的应用级语义。当分发模式时,元数据也会自动分发。
在任何情况下,模式注册中心都可能是一件好事,可以作为 文档 并帮助您查找和重用数据。而且,由于没有模式就无法解析 Avro 数据,因此模式注册表保证是最新的。当然,也可以设置一个 ProtoBuf 模式注册表,但是由于它不是操作所必需的,因此它将以尽力而为的方式结束。
Thrift
Thrift 是一个比 Avro 或 ProtoBuf 更大的项目,因为它不仅是一个数据序列化库,而且是一个完整的 RPC 框架。它也有一些不同的文化:Avro 和 ProtoBuf 标准化了单一的二进制编码,而 Thrift 则 包含 了各种不同的序列化格式(它称之为“协议”)。
实际上,Thrift 有两种不同的 JSON 编码,以及至少三种不同的二进制编码。(然而,其中一种二进制编码,DenseProtocol,仅在 C++ 实现中支持;由于我们对跨语言序列化感兴趣,所以将重点介绍另外两种。)
在 Thrift IDL 中,所有编码共享相同的模式定义:
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}BinaryProtocol 编码非常简单,但也相当浪费(编码示例记录需要 59 字节):
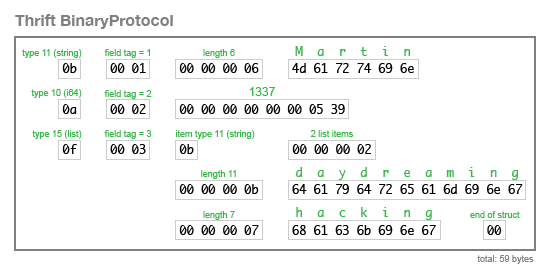
CompactProtocol 编码在语义上是等价的,但使用可变长度整数和位压缩将大小减小到 34 字节:
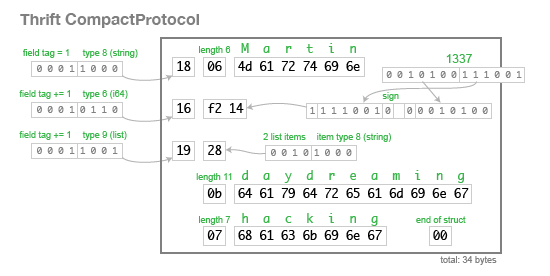
可以看到,Thrift 的模式演进方法与 ProtoBuf 相同:在 IDL 中手动为每个字段分配一个 Tag 标签,并且 Tag 标签和字段类型存储在二进制编码中,这使得解析器可以跳过未知字段。Thrift 定义了一个明确的列表类型,而不是 ProtoBuf 的重复字段方法,但是在其他方面两者非常相似。
但从哲学的角度来看,各个库是非常不同的。Thrift 喜欢一站式服务的风格,它提供了一个完整的集成 RPC 框架和许多选择(具有不同的跨语言支持);而 ProtoBuf 和 Avro 似乎更遵循“做一件事,并做好它”的风格。
| 从这篇文章来看,MessagePack 就是一个先天不足的序列化协议。它只能增加字段,而且只能在最后增加字段。但是,却不能删除字段。这对于接口升级非常不利。 |