Raft 论文摘要(一)

前一段时间,在一次开组会的时候,给小组成员简单介绍了一下 Raft 协议。大概四年前读过 Raft 的论文,这次分享的时候,好多好多细节都忘了。所以,再次把 《In Search of an Understandable Consensus Algorithm》 这篇论文找出来,重读一遍,做个笔记和摘要,方便后续学习和复习。
Abstract
Raft is a consensus algorithm for managing a replicated log.
开篇摘要就点出了 Raft 的特点: Raft 是一种管理复制日志的共识算法。
In order to enhance understandability, Raft separates the key elements of consensus, such as leader election, log replication, and safety, and it enforcesa stronger degree of coherency to reduce the number of states that must be considered.
为了增强可理解性,Raft 将共识分解成几个关键元素,例如 Leader 选举,日志复制,以及安全性等;同时,为了降低需要考虑的状态的数量,还强制实施了更强的一致性。
1. Introduction
Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members.
共识算法是将一组机器作为一个工作整体,以应对个别机器宕机造成的不可用性。
Paxos has dominated the discussion of consensus algorithms over the last decade.
只从 [Google Chubby] 发表以后,借助于 Google 在分布式系统领域的强大影响力,Paxos 一下子就成了共识算法中的核心,在共识算法领域占据统治地位。
Paxos is quite difficult to understand, inspite of numerous attempts to make it more approachable.
如果 Paxos 容易理解, Raft 可能就不会出现了。哈哈哈😄
Our approach was unusual in that our primary goal was understandability: could we define a consensus algorithm forpractical systems and describe it in a way that is significantly easier to learn than Paxos?
从这句话中可以看出,提出 Raft 的首要目的是:可理解性,这个目标确实非比寻常。
It was important notjust for the algorithm to work, but for it to be obvious whyit works.
知其然,也知其所以然。
In designing Raft we applied specific techniques to improve understandability, including decomposition (Raftseparates leader election, log replication, and safety) and state space reduction (relative to Paxos, Raft reduces thedegree of nondeterminism and the ways servers can be inconsistent with each other).
为了提高 Raft 的可理解性,作者使用了解耦和减少状态空间两个方法。
It has several novel features:
Strong leader
Leader election: Raft uses randomized timers to elect leaders.
Membership changes: Raft’s mechanism for changing the set of servers in the cluster uses a new joint consensus approach where the majorities oftwo different configurations overlap during transitions.
2. Replicated state machines
Replicated state machines are used to solve a variety of fault tolerance problems in distributed systems.
Examples of replicated state machines include [Google Chubby] and [Apache ZooKeeper].
Replicated state machines are typically implementedusing a replicated log, as shown in Figure 1. Each serverstores a log containing a series of commands, which itsstate machine executes in order. Each log contains thesame commands in the same order, so each state ma-chine processes the same sequence of commands.
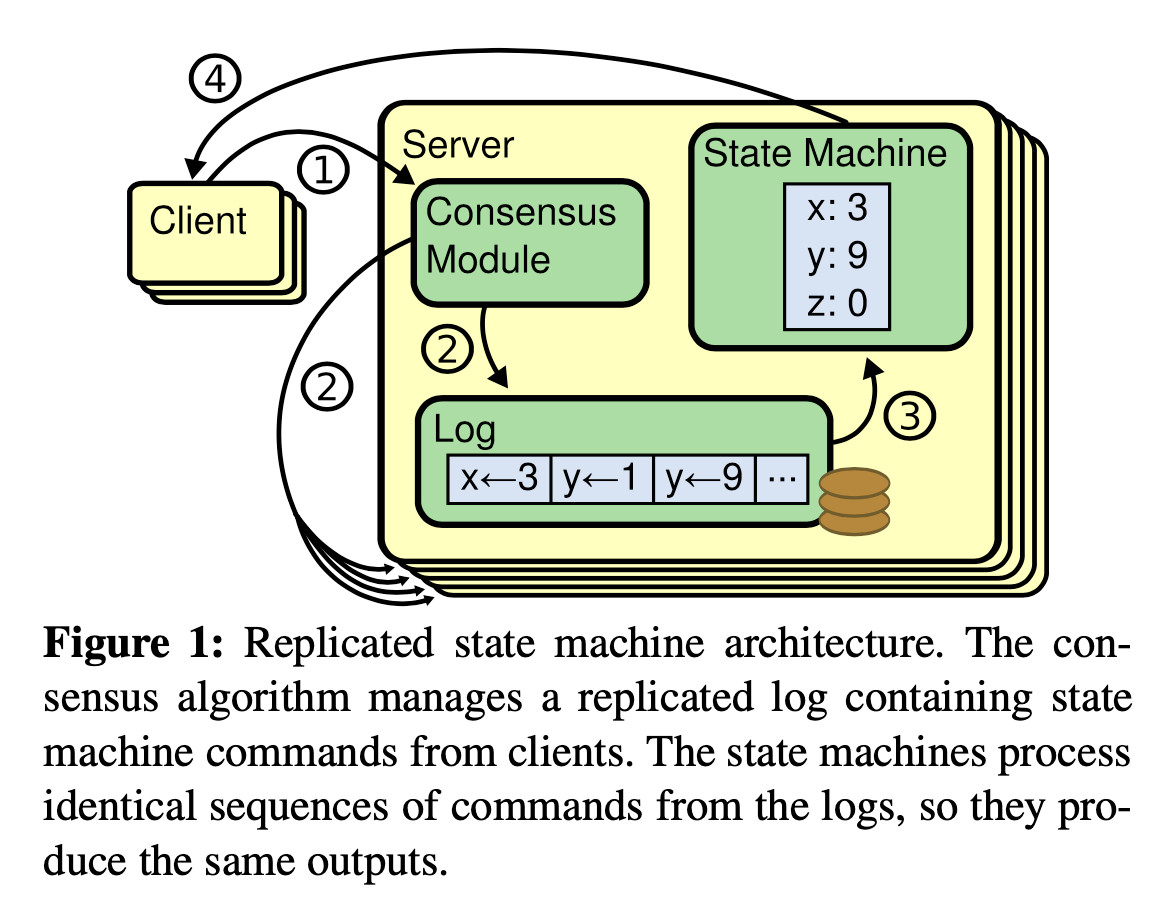
每台复制状态机存储着包含一系列命令的日志,而且这些命令按照顺序执行。由于每个日志包含着相同相同顺序的相同命令,所以每个机器就处理着相同顺序的命令,结果就是所有机器执行的结果都是一样的。
Keeping the replicated log consistent is the job of theconsensus algorithm.
Consensus algorithms for practical systems typicallyhave the following properties:
They ensure safety(never returning an incorrect result) under all non-Byzantine conditions, includingnetwork delays, partitions, and packet loss, duplication, and reordering.
They are fully functional (available) as long as anymajority of the servers are operational and can communicate with each other and with clients.
They do not depend on timing to ensure the consistency of the logs: faulty clocks and extreme messagedelays can, at worst, cause availability problems.
In the common case, a command can complete assoon as a majority of the cluster has responded to asingle round of remote procedure calls; a minority ofslow servers need not impact overall system performance.
最后一点到时没有想到。推敲一下,确实如此,响应快的多数派机器已经达成共识,返回客户端结果了。效应慢的机器,只要跟在后面跑就好。
3. What’s wrong with Paxos?
Paxos first defines a protocol capable of reachingagreement on a single decision, such as a single replicatedlog entry. We refer to this subset assingle-decree Paxos.Paxos then combines multiple instances of this protocol tofacilitate a series of decisions such as a log (multi-Paxos).
Paxos 与 multi-Paxos 什么区别?
Paxos has two significant drawbacks.
The first drawback is that Paxos is exceptionally difficult to understand.
The second problem with Paxos is that it does not provide a good foundation for building practical implementations
One reason is that there is no widely agreedupon algorithm for multi-Paxos.
Furthermore, the Paxos architecture is a poor one for building practical systems;
Another problem is that Paxos uses a symmetric peer-to-peer approach at its core
Paxos 的两个缺点:难以理解 和 缺乏良好的构建基础。
If aseries of decisions must be made, it is simpler and fasterto first elect a leader, then have the leader coordinate thedecisions.
这种方式更优?还是 Leader 主导更优?有待专门文章来论证。
Each implementation begins with Paxos, discovers the difficulties in implementing it, and then develops a significantly different architecture.
[Google Chubby] 的论文中,似乎也证实了这一点:
There are significant gaps between the description ofthe Paxos algorithm and the needs of a real-world system. . . . the final system will be based on an unproven protocol.
有机会把 [Google Chubby] 的论文也读一下。
参考资料
[Google Chubby] The Chubby lock service for loosely-coupled distributed systems
[Apache ZooKeeper] ZooKeeper: Wait-free coordination for Internet-scale systems