Raft 论文摘要(二)

在上一篇文章中,通过阅读 《In Search of an Understandable Consensus Algorithm》 前三节的内容,对论文的大致内容做了简介,简单说明了一下 Replicated state machines 的用途以及 Paxos 本身存在的问题。
4. Designing for understandability
several goals in designing Raft:
it must providea complete and practical foundation for system building;
it must be safe under all conditions and available under typical operating conditions;
it must be efficient for common operations.
Our most important goal — and most difficult challenge — was understandability.
从这里可以看出,Raft 设计的初衷就是为了易于理解和便于构建。
There were numerous points in the design of Raft where we had to choose among alternative approaches. In these situations we evaluated the alternatives based on understandability.
总之,一切出发点就是易于理解。但是,这里就有一个疑问了,在整个设计中,有没有什么地方为了理解而舍弃效率?有哪些地方?如何改进?
We used two techniquesthat are generally applicable:
The first technique is the well-known approach of problem decomposition: wherever possible, we divided problems into separate pieces that could be solved, explained, and understood relatively independently.
Our second approach was to simplify the state spaceby reducing the number of states to consider, making the system more coherent and eliminating nondeterminism where possible.
从目录来看,这两个
We used randomization to simplify the Raft leader election algorithm.
在选举中,定时器的时长是随机的,确实可以减少冲突发生的概率。
5. The Raft consensus algorithm





Raft implements consensus by first electing a distinguished leader, then giving the leader complete responsibility for managing the replicated log.
Raft decomposes the consensus problem into three relatively independent subproblems:
Leader election: a new leader must be chosen when an existing leader fails;
Log replication: the leader must accept log entries from clients and replicate them across the cluster, forcing the other logs to agree with its own;
Safety: the key safety property for Raft is the State Machine Safety Property in Figure 3: if any serverhas applied a particular log entry to its state machine,then no other server may apply a different commandfor the same log index.
5.1 Raft basics
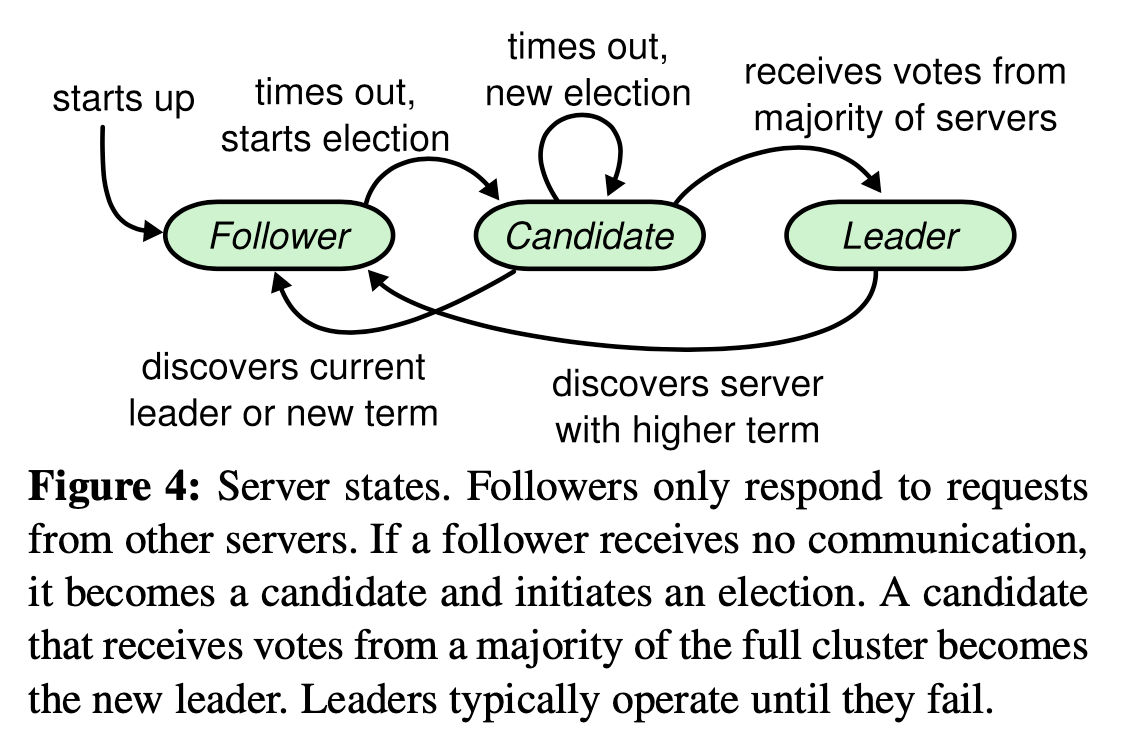
At any given time each server is in one of three states: leader, follower, orcandidate. In normal operation thereis exactly one leader and all of the other servers are fol-lowers.
Followers issue no requests ontheir own but simply respond to requests from leaders and candidates.
The leader handles all client requests.
Candidate is used to elect a new leader.
Follower 不处理请求,只响应 Leader 和 Candidate 的请求。
Leader 处理所有的 Client 请求。
Raft divides time intotermsof arbitrary length. Terms are numbered with consecutive integers. Each term begins with anelection. Raft ensures that there is at most oneleader in a given term.
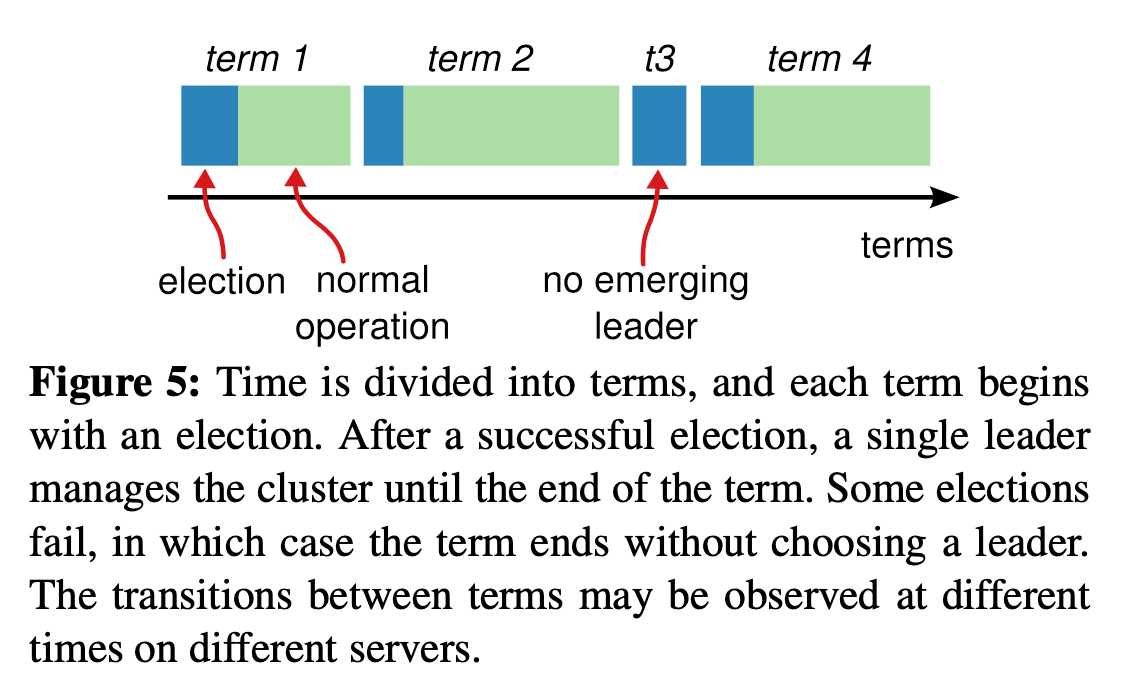
Terms act as a logical clock in Raft. Each server stores a current term number, which increases monotonically over time. Current terms are exchanged whenever servers communicate; if one server’s current term is smaller than the other’s, then it updates its current term to the larger value. If a candidate or leader discovers that its term is out of date, it immediately reverts to follower state. If a server receives a request with a stale term number, it rejects the request.
Terms 在 Raft 中相当于一个逻辑时钟。
Raft servers communicate using remote procedure calls(RPCs):
RequestVote RPCs are initiated by candidates during elections.
AppendEntries RPCs are initiated by leaders to replicate log entries and to provide a form of heartbeat.
A third RPC for transferring snapshots betweenservers.
Raft 服务器之间使用 RPC 通信,前两种 RPC 格式是必须的,最后一种是附加的。
5.2 Leader election
Raft uses a heartbeat mechanism to trigger leader election.
Leaders send periodic heartbeats (AppendEntries RPCs that carry no log entries)to all followers in order to maintain their authority.
If a follower receives no communication over a period of time called the election timeout, then it assumes there is no viable leader and begins an election to choose a new leader.
参考资料
[Google Chubby] The Chubby lock service for loosely-coupled distributed systems
[Apache ZooKeeper] ZooKeeper: Wait-free coordination for Internet-scale systems